UNIVERSITY OF SOUTHAMPTON
Faculty of Physical and Applied Science
School of Electronics and Computer Science
Networked agency
By Philip Sheldrake
Supervisors: Prof Dame Wendy Hall and Dr Kieron O’Hara
A progress report submitted for continuation towards a PhD
19th May 2017
www.philipsheldrake.com/research
This report is informed by Philip Sheldrake’s contribution to the free and open source hi:project. It is licensed under a Creative Commons Attribution 4.0 International License, a Free Culture License.
Abstract
Personal agency is the potential to ‘act otherwise’, the capacity to participate, to start something, to act independently. Here I examine the theoretical perspectives of agency and consider how it might be effected and transformed in sociotechnical terms – networked agency – with reference to concepts of algorithmic control, trust, sovereignty, privacy, and decentralisation.
I introduce a sociotechnical ‘stack’ I call the Internetome, and skin, an assembling of the biological, psychological, informational, and interfacial. I describe the hi:project – a human-computer interaction concept motivated by the intention to protect and grow personal agency – and detail the beginnings of a network map of projects that have similar intentions.
The report concludes by scoping future work.
Table of contents
- 1. Introduction
- 1.1. Research questions
- 1.2. Report structure
- 2. Sociological concepts of agency
- 2.1. A dichotomy
- 2.2. A unification
- 2.3. A return to dualism?
- 2.4. An appropriate concept
- 2.4.1. It’s complex
- 2.4.2. In the context of social machines
- 2.4.3. Agencement
- 3. The sociotechnical agent
- 3.1. Algorithmic control
- 3.2. Trust
- 3.3. Self-sovereign
- 3.3.1. Self-sovereign identity
- 3.3.2. Self-sovereign technology
- 3.4. Privacy and personal data
- 3.4.1. In disarray
- 3.4.2. Contextual integrity
- 3.4.3. Click to enable
- 3.4.4. Metaphorically speaking
- 3.4.5. Practically speaking
- 3.4.6. A bridge
- 3.4.7. The individual at level 4
- 3.5. Agents in cyberspace
- 3.5.1. Decentralisation
- 3.5.2. The Stack
- 3.5.3. Skin
- 3.6. The Internetome
- 3.6.1. Consensus protocols
- 3.6.2. Digital devices vertex
- 3.6.3. Post-TCP/IP networking vertex
- 3.6.4. Semantic vertex
- 3.6.5. Legal vertex
- 3.6.6. Social vertex
- 3.6.7. Interface vertex
- 4. The interface
- 4.1. Catering to difference
- 4.1.1. Context
- 4.1.1.1. Separation
- 4.1.2. CC/PP and ARIA
- 4.1.3. Model-based UI
- 4.1.4. Service-oriented / Semantic UI
- 4.1.5. Distributed UI (DUI) and liquid software
- 4.1.6. Interaction-Oriented Software Engineering (IOSE)
- 4.1.1. Context
- 4.2. Human-Data Interaction
- 4.3. The human interface and the hi:project
- 4.3.1. The project’s purpose
- 4.3.2. The hi:project – nomenclature and definition
- 4.3.3. Adaption
- 4.3.4. The technology
- 4.3.4.1. The hi:framework
- 4.3.4.2. The hi:engine
- 4.3.4.3. The hi:profile
- 4.3.4.4. The hi:components
- 4.3.4.5. The hi:ontology
- 4.3.4.6. The hi:cache
- 4.3.4.7. The hi:coin
- 4.3.5. The objectives
- 4.3.5.1. Personal data and privacy
- 4.3.5.2. Citizen-centric / redecentralised Internet and Web
- 4.3.5.3. Accessibility and digital inclusion
- 4.3.6. The business case for dissemination
- 4.3.7. Next steps
- 4.1. Catering to difference
- 5. The ecosystem for networked agency
- 5.1. Mapping the ecosystem
- 5.2. Screenshots
- 6. Future research
- 6.1. Research questions
- 6.2. Timeline
- 7. Bibliography
List of figures
Figure 1 – Privacy settings in the Firefox browser, ver. 52.0
Figure 2 – Centralized, Decentralized and Distributed Networks, Paul Baran, 1964
Figure 3 – The sociotechnical imbalance of centralised technology
Figure 4 – The sociotechnical balance with distributed technology
Figure 5 – Portraying the loci of centralisation on Bratton's The Stack
Figure 6 – The six layers of Bratton's The Stack, portraying three paths (Bratton, 2015, p. 66)
Figure 7 – A 'stack'; the Internetome
Figure 8 – Construction of the human interface
Figure 9 – 115 projects, clustered by aligned purpose
Figure 10 – 115 projects, clustered by project dependencies
1. Introduction
To be concerned with the health and resilience of living systems including our planet, our societies, and our organisations, is to be concerned with the components of those systems and how they come together. Amongst “the truths revealed by nature’s living processes” (Schumacher, 1973) is the criticality and interdependence of agency and distributed network topologies. In human terms, that coming together is increasingly mediated by digital technologies and services, and it is then critically important to qualify the impact such innovations have on our personal agency.
Sociologists appreciate that agency – the potential to make a difference as one wishes – is unevenly distributed. Subscribing to a humanist emancipatory ideal dedicated to human flourishing on top of a natural self-interest in nurturing resilient living systems, one might want for digital technologies and services to expand agency on the whole, attenuate pre-digital constraints, and potentially spread it around a little more evenly.
Unfortunately, the current manifestation of digital technologies appears to exert the opposite effect, enabling new control mechanisms at massive and unprecedented scale by both the state and select private sector participants. Just as concerning, the individual technology user appears to play the role of contented collaborator to these ends, a modern tragedy of the commons by which we all undermine essential societal structures in our satisfied, ignorant placidity. Right now, just aiming to re-establish the pre-digital status quo can appear sufficiently ambitious; a double challenge when the individual doesn’t perceive the need and entrenched interests at the structural level show little sign of relaxing their grip.
The business of centralising has it easy. First, the corresponding technological architecture is comparatively simple. Second, the corresponding business model – the opportunity to develop direct or indirect revenue streams – is readily apparent. Third, the ecosystem is very small and comparatively straightforward to understand, and this from observation alone1 appears to be relished by our democratic representatives and their desire for control. “…the question remains: are we going to allow a means of communications which it simply isn’t possible to read. My answer to that question is: ‘No we must not’” (David Cameron, as quoted in Hope, 2015). When a UK Prime Minister argues in these terms, any corresponding policy implementation must rely on the interventions of centralised communications service providers. The following year, while noting the imperative for competition policy to prevent abuse of market dominance, the UK Government described digital platforms as convenient, empowering, and worthy of support; they definitely should not be subject to any regulation that might erode their immediate advantages (UK Government, 2016).
By contrast, decentralisation requires technologies to both effect and preserve distributedness, many of which are still in the earliest stages of development. In ‘getting out of the way’, organisations propagating this technology remove themselves from the mediating position synonymous with monetisation leaving them with no immediately obvious business model2. The ecosystem is so fragmented and the commercial potential so uncertain that it appears very few have been motivated to map it broadly, and with the exception of Iceland’s Pirate Party (France-Presse, 2016), I can find no significant reference to a mainstream political party embracing this apparent ‘free for all’.
In short, it appears that the agency facilitated by and supportive of trustworthy, private, accessible, distributed networks is opposed by both commercial and political structures. Yet, from private conversations with individuals employed by the commercial centralisers and some of the public communications from such companies (Cook, 2016; Yadron, 2016), it seems such deleterious effect may be simply a consequence of a company’s success rather than a goal per se, and while it is too easy to adopt a cynical attitude towards the motivations of politicians of all political persuasions, it would seem unrealistic to assume a sizeable fraction let alone a majority is intent on realising the societal characteristics explored by dystopian novelists such as Huxley and Orwell. Agency is then being subjugated and relegated by commercial and political structures whether the participating agents know it or not, or indeed like it or not.
1.1. Research questions
Agency and a distributed network topology are interdependent, and both are considered critical to sustainability – the health and resilience of living systems including our planet, our societies, and our organisations. My research explores the questions:
RQ1 – How might we define the sociotechnical agent?
RQ2 – How is this agent effected by current and future technical architectures and services?
RQ3 – What are the opportunities and challenges for the associated ecosystem of projects?
1.2. Report structure
In Section 2 I review agency from various theoretical perspectives, searching for one that appears best suited to my research – agencement. Section 3 applies this theoretical perspective and situates it in terms of algorithmic control, trust, and privacy. I present the need to augment the very definition of agent (i.e. ourselves) in order that the agent may better sustain itself, and introduce a sociotechnical ‘stack’ to structure the analyses of trustworthiness, privacy, equality, and distributedness, and therefore agency. I conclude that one part of this ‘stack’ is particularly critical and yet appears to be receiving the least attention in the context here – one’s interface into and onto the digital world.
In Section 4, I describe the hi:project, a human-computer interaction concept motivated by the intention to protect and grow personal agency, and detail the beginnings of a network map of projects that have similar intentions in Section 5. The report concludes by scoping future work.
2. Sociological concepts of agency
2.1. A dichotomy
“Agency refers not to the intentions people have in doing things but to their capability of doing those things in the first place.” It implies power (Giddens, 1986).
“To be able to 'act otherwise' means being able to intervene in the world, or to refrain from such intervention, with the effect of influencing a specific process or state of affairs.” Giddens notes that to act is to ‘make a difference’ and that losing this facility is the cessation of agency. He also emphasises that it isn’t so much a collection of discrete acts but part and parcel of the flow of daily life.
Giddens and Sutton (2014) describe the 'problem' of agency and structure. They note the early sociologists’ insistence that society and social forces (the structure) are things that limit individual choice and freedom, specifically Emile Durkheim's extension of the ideas of Herbert Spencer and August Comte on groups and collectivities that contributed in part to defining the very discipline of sociology.
The structure / agency question is described as one of several related conceptual dichotomies in sociology “rooted in sociology's attempts to understand the relative balance between society's influence on the individual (structure) and the individual's freedom to act and shape society (agency)." (Giddens and Sutton, 2014)
The emphasis placed on agency by sociologists has ebbed and flowed. Parsons (1935) pointed out that the positivistic approach obscured the fact that man is, in essence, an active, creative and evaluating creature. Positivists homed in on “causes” and “conditions”, and labelled attempts to talk in terms of ends, purposes and ideals as “teleology” and therefore incompatible with positive science. In modern parlance, the positivists obsessed with structure over agency.
Parsons criticised the positivists for their clearly incorrect regard for the human as inanimate and their corresponding neglect of agency. He pointed out that ends are not a given but quite simply the element of rational action beyond the scope of positive science. This is manifest in the extreme as behaviourism, specifically denying the role of humans in scientifically explaining their actions.
Parsons then was early to hint at a reconciliation if not integration of agency and structure: “Of course the results of the analysis of human behavior from the objective point of view (that is, that of an outside observer) and the subjective (that of the person thought of as acting himself) should correspond, but that fact is no reason why the two points of view should not be kept clearly distinct. Only on this basis is there any hope of arriving at a satisfactory solution of their relations to each other.” Parsons called this reconciliation action theory.
Social theory can never neglect agency again; quite the opposite. The “revolutionary advances in electronic technologies and globalization are transforming nature, reach, speed, and loci of human influence. These new realities present new challenges and vastly expand opportunities for people to exercise some measure of control over how they live their lives.” (Bandura, 2006). Bandura describes the growing, technologically enabled primacy of human agency in education, health and occupational activities. He goes so far as to assert that the very effectiveness of Internet use is contingent upon personal enablement (Bandura, 2006, 1997). By this I believe he is comparing and contrasting technical and social architectures. Given that the Internet’s design emphasises a distributed architecture and independent, agentic nodes, Bandura expects to see this mirrored in society for the full sociotechnical benefit to be realised.
Empirical studies have shown that the Internet facilitates agency, benefitting “a range of citizen-activists” including: protesters against corrupt and dictatorial regimes; traditionally marginalised, excluded or stigmatised communities; transnational social movements; electoral underdogs; and alternative media producers (Coleman and Blumler, 2009).
2.2. A unification
To Giddens (2014), structure and agency are inseparable as two sides of the same coin. Whereas structure had been considered primarily a constraint, Giddens also identifies it as enabling of individuals. Moreover, the repeated actions of many individuals reproduce and indeed change the social structure, a structure defined in terms of rules and resources that enable such reproduction over time rather than as some dominating external force (Giddens, 1986; Giddens and Sutton, 2014).
Structure and agency define each other. Giddens’ structuration theory moves from dividing our object of study into separate, paired elements, to considering the two as interdependent, no longer separate or opposed; from a dualism to a duality (William A. Jackson, 1999).
The duality of structure is presented as (Giddens, 1986):
Structure(s) – Rules and resources, or sets of transformation relations, organized as properties of social systems
System(s) – Reproduced relations between actors or collectivities, organized as regular social practices
Structuration – Conditions governing the continuity or transmutation of structures, and therefore the reproduction of social systems.
As Giddens describes it, “the structural properties of social systems are both medium and outcome of the practices they recursively organize.”
A theory of agency is equally important to cultural studies. Barker (2007) identifies the concept as commonly associated with notions of freedom, free will, action, creativity, originality, and the very possibility of change through the actions of free agents. He asserts that agency is unevenly distributed because it’s “socially and differentially produced”, and describes culturally generated agency as being enabled by differentially distributed social resources giving rise to “various degrees of the ability to act in specific spaces”. In other words, agency is determined by a socially constituted capacity to act.
Giddens’ structuration theory is not unchallenged, per the greater emphasis lent structure by Barker, and also Archer’s critique of structuration theory’s very essence.
2.3. A return to dualism?
Archer (2003) points out the lack of consistent definition of either structure or agent before offering a working definition based on slim agreement: in some sense 'structure' is objective, whilst in some sense 'agency' entails subjectivity.
She identifies some inadequacies relating to the “popular desire” to “transcend” the divide between objectivity and subjectivity altogether based on the recognition of ontological inseparability by which each enters into the other's constitution. In particular, Archer (1995) contends that structuration theory is incompatible with emergence. Its treatment of structure and agency as inseparable is contradictory to “the very notion of ‘emergent properties’ which are generated within socio-cultural systems” because “such structural and cultural features have autonomy from, are pre-existent to, and are causally efficacious vis-à-vis agents.”
She asserts that the ways in which structure influences agents cannot be simple, cannot be deterministic or Newtonian in its causes-and-effects, but rather then might well involve the properties and powers of agents themselves (Archer, 2003). Her justification invokes reflexivity – by which our self-analysis affects us and our analyses. Low reflexivity is then associated with the individual being shaped predominantly by her environment, and high reflexivity by her shaping her own way in the world.
“The account of how structures influence agents ... is entirely dependent upon the proposition that our human powers of reflexivity have causal efficacy – towards ourselves, our society and relations between them. However, reflexivity, which is held to be one of the most important of personal emergent properties, is often denied to exert causal powers – in which case it becomes considerably less interesting or of no importance at all in accounting for any outcome.” In other words, as high as a person’s reflexivity may be, it’s unlikely to effect structural change alone.
Archer identifies two extremes inbetween which her theory is situated: one whereby our thoughts explain nothing about our actions because they have no independent power over our actions; and another that accepts a causality of thoughts to deeds but considers the thoughts to have been internalised from society rather than anything we might originate ourselves. She seeks explanation for decision-making processes. She argues that one: (a) has one’s own subjectivity that is real and influential; (b) lives in a social world with distinct properties and powers that may constrain or enable one’s actions ("causally influence"); and (c) is capable of reflexively monitoring oneself whilst the social structure cannot. One is then able to adopt a 'stance' towards one’s social context in a way the structure cannot reciprocate.
In a departure from structuration theory, Archer contends that these three elements must then require consideration of 'structure' and 'agency' as two distinctive and irreducible properties and powers, and that human reflexive deliberations play a crucial mediation role. This in turn requires that such ‘internal conversation’, in mediating intentionally and differently, fallibly and corrigibly, be attributed three properties: it must be (a) genuinely interior, (b) ontologically subjective, and (c) causally efficacious.
Archer attributes the capacity for reflexive monitoring to a subjective agency and asserts that structure is “in some sense” objective and its causal efficacy dependent on agentic evocation. Nevertheless, if “reflexively monitoring” is taken to encompass the potential to interpret and respond (the agency), we must consider the non-human (i.e. technological) capacity for interpretation and response and whether such capacity might be agentic and/or structural, and if structural in some way then perhaps rendering a structural subjectivity in some way.
Social cognitive theory (SCT) seeks to explain behavioural development in terms of learning-by-observing and in so doing focuses on one’s reflexive monitoring. Bandura (2006) notes that SCT rejects a duality between human agency and social structure. He asserts (1989) a model of emergent interactive agency: “persons are neither autonomous agents nor simply mechanical conveyers of animating environmental influences. Rather, they make causal contribution to their own motivation and action within a system of triadic reciprocal causation.” That triad is personal factors, behavioural factors, and environmental factors.
Agency may be exercised: through self-belief of efficacy – cognitive, motivational, affective and selection processes; through goal representations – forethought and anticipation; and through anticipated outcomes. Unsurprisingly, this means SCT regards structure and agency as interrelated, “people are contributors to their life circumstances, not just products of them. … People create social systems, and these systems, in turn, organize and influence people’s lives” (Bandura, 2006).
Bandura address four core properties of human agency:
- Intentionality – contributing to collective intentionality
- Forethought – to consider likely future outcomes
- Self-reactiveness – to construct, motivate and regulate oneself
- Self-reflectiveness – to consider personal efficacy, thoughts and meaning.
Intentionality is the power of minds to be about, to represent, or to stand for, things, properties and states of affairs (Jacob, 2014).
Referencing Meichenbaum (1985), Schunk and Zimmerman (1994), and his earlier work (1986), Bandura writes (2006): “People who develop their competencies, self-regulatory skills, and enabling beliefs in their efficacy can generate a wider array of options that expand their freedom of action, and are more successful in realizing desired futures, than those with less developed agentic resources.”
2.4. An appropriate concept
I am searching for a concept of agency that’s not only compatible with the pervasive sociotechnical context but supportive in establishing means to help it flourish. Given the various concepts of agency explored so far, I can pose the question at the heart of this thesis in as many ways. How might the Internet, Web and associated technologies help or indeed hinder people in developing the competencies, skills and beliefs that Bandura identifies? How might they help or hinder in terms of Archer’s subjectivity, reflexive monitoring, and social causal influence? In terms of Giddens’ duality of structure?
Yet neither dualism nor duality feel compatible with my perceptions of sociotechnical systems. While it’s clearly tautological to describe a concept as artificial, they feel forced, perhaps akin to insisting a fractal be viewed at no more than two discrete scales.
2.4.1. It’s complex
The philosopher G.H. Lewes (1875) noted that “there is a co-operation of things of unlike kinds. The emergent is unlike its components insofar as these are incommensurable and it cannot be reduced to their sum or their differences.”
Johnson (2007) writes that complex systems contain a collection of many interacting objects or "agents", and points out that for many complexity scientists its study is synonymous with the joint study of agents and networks. He describes key aspects including the effect of feedback on behaviour, system openness, and the complicated mix of order and chaos.
Complexity science developed in the 1970s from cybernetics and systems theory. Bhaskar (1979) first contemplated the complexities of social science in his development of critical naturalism. He identifies the weakness of empiricism – its obsession with cause and effect and therefore its inappropriateness given the complexities of the human and human society. Referencing Bhaskar’s conclusion (1989) “that the causal power of social forms is mediated through human agency”3, Archer (2003) notes that the theory “is obviously ‘against transcendance’ because it is ‘for emergence’”.
Barker (2007), not one to let structure go under-emphasised, observes that human culture and human biology have co-evolved and are indivisible. “… human beings are both biological animals and cultural creatures. Any plausible attempt to understand them must embrace the idea of holism and complex systems analysis.”
In mapping complexity theory to social theory, Byrne and Callaghan (2013) find: “individuals are themselves complex systems”; “they possess the power of agency both individually and … collectively”; and “to say that collectivities possess agency is to say collectivities have a reality beyond the individuals who constitute them.” The authors make a fundamental argument for the nesting and interpenetration of complex social systems beyond individuals that appears entirely compatible with agencement (2.4.3).
2.4.2. In the context of social machines
As noted by O’Hara et al (2013): “Structuration is relevant to Web Science because that is what the technology does – it provides a series of constraints on behaviour, while also affording opportunities.”
Berners-Lee (1999) observes that society arises in part from constrained processes. He notes the creation of “social machines” on the Web: “processes in which the people do the creative work and the machine does the administration.” Not content with this division of labour from observation, Smart et al (2014) propose that social machines “are Web-based socio-technical systems in which the human and technological elements play the role of participant machinery with respect to the mechanistic realization of system-level processes.”
Social machines have been framed in structuration terms, so I will analyse briefly the semantics of the term by way of further explaining my unease at adopting either dualism or duality.
First, Latour (2005) explains when the application of social is unhelpful. There is nothing wrong he contends when “it designates what is already assembled together, without making any superfluous assumption about the nature of what is assembled”, but it becomes problematic when invoked “to mean a type of material.” To me, social machines has the same qualities as Latour’s example adjectives in our context here: wooden machines, steely machines, biological machines. As Latour further qualifies, the adjective social then becomes torn between designating a process of assembling (to which I will return again shortly, 2.4.3) and a specific type of ingredient. And yet this ingredient is negatively defined as not being ‘purely’ biological, linguistic, economical, natural, and positively defined in terms of achieving, reinforcing, expressing, maintaining, reproducing, or subverting the social order. Dismissively, Latour recognises social for this reason as a catch-all by which “the social could explain the social”, and recommends instead a conception in which “there is no social dimension of any sort, no ‘social context’, … no ‘social force’ is available to ‘explain’ the residual features other domains cannot account for.” Latour demands a new conception of social that, rather than proferring as a solution the existence of specific social ties that illuminate some specific social forces, offers this insight up as the puzzle on which to focus.
Second, for all its Newtonian connotations, machine is unsuited to anything relating to human relations and interactions however they may be mediated, and perhaps inappropriate, given its history, to describe technologies that are increasingly non-deterministic.
Third, while it’s apparent the two words are paired to communicate a close interrelationship, perhaps a symbiosis, it feels to me more of a juxtaposition, an abutment, an incongruity. A group of people does not work with a machine; rather individuals experience and interact with ‘the digital’ within and through their own unique contexts (4.1.1).
Gabriel Tarde sowed the seed for a concept more appropriate to the work here (Rajchman, 2000): his work initiated what became known as microsociology – interpretative analysis of everyday social interactions – that in turn influenced Deleuze and Guattari’s concept of agencement (2.4.3); and his faint anticipation of emergence led him to contemplate the facility to trace social interactions atomistically (Vargas et al., 2008), a methodological and analytical orientation taken further in Latour and Callon’s Actor-Network Theory eighty years later. An assertion by Bratton (2015) relating to the latter sets up my section on the former: as we can now entertain inordinate computational models of such traces, “the vocabulary of individual (as element) and society (as aggregated structure) is an unnecessarily reductive schema.”
2.4.3. Agencement
The French word agencement is often translated as “putting together”, “arrangement”, “laying out”, but Wise (2011) insists that as it is used in Deleuze and Guattari’s work it’s important to consider the act of arranging and organizing rather than any static result. In this context, the most common translation is assemblage, “that which is being assembled.” He notes that an assemblage does not describe a predetermined set of parts designed to make a specific whole, nor a random set for that would not constitute a whole. Rather, “an assemblage is a becoming that brings elements together.” As questions of suitability still remain about the translation of agencement to assemblage, I will simply use agencement.
Callon (2005) extends the meaning of agencement into social theory (Phillips, 2006 on Deleuze and Guattari). “Agency as a capacity to act and to give meaning to action can neither be contained in a human being nor localized in the institutions, norms, values, and discursive or symbolic systems assumed to produce effects on individuals. Action, including its reflexive dimension that produces meaning, takes place in hybrid collectives comprising human beings as well as material and technical devices, texts, etc.” According to Ruppert (2011), agencement emphasises “how agency and action are contingent upon and constituted by the sociotechnical arrangements that make them up.” In other words, instead of viewing actors atomistically and in compound, we consider each actor an agencement and a constituent of agencement.
Callon contends that these agencies include human bodies but also prostheses, tools, equipment, technical devices, and algorithms. Actors are agencements. Actors and technologies are agencements. The populations they enact via their mediations and interactions are agencements. And the populations produce the subjects, the actors. In other words, agencement permits the nesting and interpenetration of complex social systems.
The inference then is that populations are also subjective: “… an object such as a population is a ‘precarious accomplishment’, which needs to be studied rather than assumed, not a singular entity but an outcome of multiple practices.” (Ruppert, 2011; referencing Mol, 2002).
Perhaps the duality of structuration theory and the dualism of structure / agency consider agency and structure and their meld as objects whereas agencement objectifies the tension, the flow, the dynamic.
Ruppert asserts that agency is mediated by particular sociotechnical agencement, and agency is configured differently under different agencements ranging from passive identification and classification with little or no engagement, through to full engagement. Importantly she notes that as knowledge of a population is essential to governing and the allocation of rights we must question how citizens can involve themselves in enacting the population and how the citizen is then represented in that enactment.
Ruppert’s work is the perfect segue to considering the sociotechnical agent.
3. The sociotechnical agent
Ruppert invokes the concept of “data doubles”, an idea defined by Haggerty and Ericson (2000) as the surveillant agencement by which once separate surveillance related data flows are combined to render an informational facsimile of the subject; decorporealized and decontextualized. I explain the idea in general conversation by asking ‘who’ exactly gets risk assessed in the pricing of insurance, the remote biological entity or an easily accessed and machinable data double? Such process then entails a meta-agency; if the data double as representative affects the data subject’s agency, what agency does the data subject have over the corresponding dataset? We should also ask what agency the dataset and the corresponding presentation and interactivity have over the subject, especially when assembly of the data double is effected by third parties for their own purposes.
On this point, Bode and Kristensen (2016) distinguish their concept of digital doppelgänger, specifically that it is spawned and continually maintained by its subject, contextually, as distinct and separate yet dependent on and “entangled” with its corporeal subject. That’s far from the situation we find today.
3.1. Algorithmic control
“When something online is free, you’re not the customer, you’re the product.” Zittrain (2012) attributes his turn of phrase to a similar assertion made on a popular online forum: “If you are not paying for it, you're not the customer; you're the product being sold.” (Lewis, 2010). The earliest statement of this ilk appears to be Serra and Schoolman (1973): “The Product of Television, Commercial Television, is the Audience. Television delivers people to an advertiser.”
The associated idea that one’s attention might be something of value was mooted by Simon (1971). He identified that a wealth of information creates a poverty of attention, and value is attributed to anything scarce that’s in demand. This mechanism is core to many so-called Web 2.0 business models.
Berg (2012) discusses this misalignment of motivations, advocating the conceptual separation of individual-oriented and system-oriented agency. In technological terms, he refers to the front-end and back-end perspectives, with the front-end providing utility value to the user but with the monetary value derived by the service provider in the back-end, largely invisible to or indeterminable by the user. The perspective of system-oriented agency highlights this institutional behaviour and associated monetization, and therefore proposes that such social intermediaries are not treated neutrally but “as distinct and somewhat independent entities. … a third actor.”
Christl and Spiekermann (2016) talk of networks of control. They describe the interchange of our personal data (3.4) amongst loose co-operatives of companies. They describe companies having a clear disregard for their customers’ best interests, wielding the assembled data doubles to discriminate against people with specific attributes and, more insidiously, attempting to influence our behaviours at scale; to control.
Bratton (2015) draws attention to this third actor by noting the reciprocation of the app. It’s typical to consider the application’s interface as the means by which the user can interact with the world around her; how she “works on the world” to use his exact words. Nevertheless, it is also the aperture through which the algorithmic services in the cloud redraw the world for the user, and redraw the users too. Apple’s Siri (the company’s so-called intelligent personal assistant) isn’t so much used-by as a co-user. He reframes the structure / agency question for the digital age: “the platform sovereignty of the User4 … is derived not from some essential dignity of the particular human who ‘uses,’ but from the agency of the User position in relation to the envelopes against which he or she or it is situated. Any sovereignty of the User draws less probably from established legal rights than from the contradictions and slippages between how formal citizens are provided access under control regimes versus how platform envelopes provide access to all Users regardless of formal political standing. … the User layer of The Stack is not where the rest of the layers are mastered by some sovereign consciousness; it is merely where their effects are coherently personified.” Bratton concludes that structure will become increasingly dominant at the expense of agency by declaring that the “more salient design problem seems less to design for Users, as if they were stable forms to be known and served, than to design and redesign the User itself in the image of whatever program might enroll it.” While not elucidating on who or what might determine the kind of user that can be designed or the program that might provide the archetype, he asserts that we shouldn’t merely be resigned to the eventuality of humans sharing (abdicating?) agency with inhuman forms but rather embrace the many advantages thereof (personal communication5).
Bostrom (2014) forecasts a similar technological outcome in describing a “principal-agent problem” that “entails a non-human superintelligent agent acting on behalf of a human principal; an unprecedented vista that by definition demands a new set of management techniques.” Yet such management techniques remain nascent, quite possibly lagging development of such artificial intelligence. On the question of whether or not he concurs with Bratton’s optimism, Bostrom notes that we have one chance to get superintellgence right given that once a type that might be described as unfriendly exists, it would seek to prevent us from replacing or changing it. “Our fate would be sealed.”
While beyond the scope of this work, I will just note the future potential cognitive activation of Bode and Kristensen’s digital doppelgänger in the form of the noeme – the combination of a distinct physical brain function and that of an “outsourced” virtual one, becoming the corporeal subject’s intellectual “networked presence” (Kyriazis, 2015).
This side of a superintelligence, Lukas (2014), founder of the Quantified Self London Group, advocates a personal data and software environment in which “expertise is supplied rather than outsourced” and where each of us acquires “agency as sense-maker”. She is critical of those device manufacturers and service providers for whom the individual’s data is foremost a fundamental currency of their business model rather than a source of insight for the data subject. The dataset and its machining are shaped by the providers’ imperatives rather than the agentic needs or aspirations of the individual. In language closely associated with VRM Lukas insists: “We can’t treat individuals as data cows to be milked for the data bucket."
Vendor relationship management (VRM) tools are customers’ counterpart to vendors’ customer relationship management (CRM) systems. VRM tools give customers greater control; as the sub-title of The Intention Economy (Searls, 2012) puts it, it’s When Customers Take Charge. With such tools, “liberated customers enjoy full agency for themselves and employ agents who respect and apply the powers that customers grant them” [original emphases]. We can generalise the role beyond that of customer to any and all the individual might occupy in interaction with other parties; indeed, in terms of anything one might wish to accomplish. Such capabilities may be provided by intelligent agents, although we must remain cognizant of Berg’s (2012) third actor implications in their design and deployment.
Barry (2001) considers the deeper and perhaps more sinister implications of this kind of system-oriented agency. Referring to the disciplining techniques of power described by Foucault whereby individuals are conditioned to align their behaviours with the interests of the source of power wielding the disciplining strategy, Barry makes the distinction: “Discipline implies normalisation: the injunction is ‘You must!’ In contrast, interactivity is associated with the expectation of activity; the injunction is ‘You may!’”
On the face of it, ‘You may!’ may be read as ‘You may act otherwise!’, our starting definition of agency; yet Barry advises caution. Interactivity may have different significance in different situations, potentially becoming associated with particular political strategies and other ideas. “Through the use of interactive devices, political doctrine can be rendered into technical form. … Politics does not circulate just through the flow of ideologies or rationalities of government, but through diagrams, instruments and practices.” This corresponds to McLuhan’s (1964) assertion that the medium is the message: “... the personal and social consequences of any medium – that is, of any extension of ourselves – result from the new scale that is introduced into our affairs by each extension of ourselves, or by any new technology.”
Jarrett (2008) explores a specific case of Foucauldian disciplining within Barry’s construct. She observes that by allowing ‘play’, interactivity assumes the a priori power to act. As play isn’t governed rigidly by the technology, the user is considered to have both agency and freedom, constituting “the ideal, active neoliberal citizen”, an ideal that the user then propagates by her very interaction.
Yet it would be incorrect to assume a stasis is achieved as agents continue to respond and modulate behaviours according to the structural frame in which they live. PEN America, an organisation that exists to protect open expression in literature and related arts, reported in 2013 that writers are engaging in self-censorship directly attributable to their concerns about government surveillance. Approximately a quarter of writers surveyed had curtailed or avoided social media and had deliberately avoided certain topics in phone and email conversations (Chilling Effects, 2013).
Castells (2002) expresses concern at such control mechanisms manifest in the technologies of identification, of surveillance, and of investigation. “All rely on two basic assumptions: the asymmetrical knowledge of codes in the network; and the ability to define a specific space of communication susceptible of control.” Fuchs et al (2012) put it quite simply: “The Internet enables a globally networked form of surveillance”, leading to what Zuboff (2015) describes as “an emergent logic of accumulation in the networked sphere” she labels Surveillance Capitalism. As web users engage with popular Internet and Web services, “they enter private domains that come with new terms of entry. We can access the data we have turned over to them, but only in exchange for willing submission to, among other conditions, the forms of monitoring and control facilitated by the interactive infrastructure.” (Andrejevic, 2007).
Hill (2012) notes that the responsibility for the translation of personal data into information has passed from the state to corporations meaning that “multinational corporations are manipulating what is stored and what is considered ‘good’ information”, relegating or discarding other stuff that cannot then be socialized and is then consequently forgotten. He is alert to social conditioning (described as our actions taken hostage) and the usurpation of roles (a dehumanisation), leaving “human (reflexive) thought replaced with computer (determinant) thought.”
A similar disciplining concern may be inferred from Couldry (2014) when he writes: “… we must be wary when our most important moments of ‘coming together’ seem to be captured in what people happen to do on platforms whose economic value is based on generating just such an idea of natural collectivity.”
Couldry posits that the success of some social media services – he refers to Facebook – is based not just on connecting us to our immediate friends and family, but by invoking a broader ‘we’, a collectivity extending way beyond our immediate network. In making this broader connection, the service is setting itself up as the arbiter of what’s happening, what’s trending, and so, importantly, by accumulation, what matters. By corollary, the user is discouraged at best and disempowered at worst from making this assessment herself.
Facebook was accused of bias in the selection of stories for its ‘Trending’ section in the run up to the United States Presidential Election 2016 (Lee, 2016). Interestingly, the accusation focuses on human intervention in the curation of the section, as if there is an implicit assumption that the underlying algorithms would be neutral left to do their work. Wired Magazine (Lapowsky, 2016) corrects that misconception: “Algorithms themselves act as a reflection of their creators’ judgment in the search results they generate and the News Feed items they surface, automating the act of editorial decision-making.” The article notes that people expect such decisions to be independent of human judgement or bias, “that the machines can rise above the differences that divide us. … When that turns out not to be the case, people feel betrayed.” Eslami et al (2015) found that 25 of 40 Facebook users they interviewed were unaware Facebook even employed algorithms for such things.
Bratton (2015) generalises this disconnect between user and platform: “Platforms don’t look like how they work and don’t work like how they look.”
Whether it’s purely an output of software, or an output then subject to a human filter, we are distanced from the selection criteria. As Couldry puts it: “… your story, my story – really doesn't matter.” One might even say that your data double’s story and my data double’s story do not matter; the only thing that matters is a third party’s opaque interpretation of many data doubles in the aggregate. This unprecedented distance and opacity erodes one’s facility to make a difference, one’s agency. It also undermines the social agency of previously enacted populations that are swept up in this subjective, biased distillation of the ‘bigger picture’.
Couldry observes that such machination “fractures the space of discourse”, alienating individuals from the space in which they think they live – in which they think and act – and delivering them into a stream of algorithmically governed sequences. He expresses concern that a new model of social knowledge is emerging that is, for the first time, independent of direct human action and meaning-making.
McCrossan (2015) makes a similar observation encompassing social apps, wearable technologies and the ‘new normal’ of privacy, i.e., the lack thereof. She notes they “are generating new powers of agency for providers vying to have a piece of the space in our heads; they can understand how we behave, know what we do, and share content well outside our own sense of domain.” Whereas Couldry implies that the user remains largely unaware, McCrossan notes this is “beginning to give us a detached sense of agency.” Lanier (2013) describes the enthusiasm of the entrepreneurial owners to ‘make a difference’, yet is alarmed at the consequential attenuation of ordinary people’s agency.
Lash (2002) explains why our interface with our increasingly technological life is of critical concern: “In technological forms of life we make sense of the world through technological systems. As sense-makers, we operate less like cyborgs than interfaces. These interfaces of humans and machines are conjunctions of organic and technological systems. ... We do not merge with these systems, but we face our environment in our interface with technological systems.”
Lash points out that we must now operate as man-machine interfaces navigating through technological forms of natural life, facets of which are increasingly constituted at a distance unknown to pre-technological life forms.
We are contemplating “the technologization of life itself, the mediatization of life itself.” (Lash, 2007). “When media are ubiquitous, interfaces are everywhere. The actual becomes an interface. People and other interfaces are connected by protocols that connect an ever-greater variety of interfaces with one another.”
Lash compares the software algorithm with genetic coding, conveying by analogy its role in constituting social life as DNA constitutes biological life. Yet unlike our experience of previous social code expressed in law and in utterance and in behaviour, the generative algorithm is “compressed and hidden”. “A society of ubiquitous media means a society in which power is increasingly in the algorithm”; a perspective shared and a conclusion echoed by Pasquale (2015).
This riles Lanier (2013). For him, conceding to the algorithm is akin to technological determinism, a future in which people cannot invent their own lives, where we are denied dignity and self-determination. Pasquale notes the paradox whereby the “staggering” breadth and depth of data in the so-called information age is out of our reach. It is information only for those who have the access to and mastery over the data, ie, the few. More optimistically, Eslami et al (2015) conclude that encouraging “active engagement” of the user with algorithms “can offer users agency, control, and a deeper relationship with the platform itself.”
3.2. Trust
Given the argument for considering the agencement of the human and her information technology, it follows that if we cannot trust the technology we cannot trust ourselves, and if we cannot trust ourselves how can we trust each other? This includes our exo-brain (not yet in the noeme sense but rather our computing devices, most notably our smartphones and pervasive digital services) and our exo-peripheral nervous system (our digitalised sensory environment).
I will define trust as I mean it here.
“In the words of the poem, ‘Yesterday upon the stair, I met a man who wasn’t there.’ This was meant to be humorous: we can presume its author (one Hughes Mearns, since you ask) wasn’t expecting it to be prescient. Nonetheless, it was.”
In the opener to their book, O’Hara and Shadbolt (2008) home in immediately on the relatively recent dematerialisation and time-shifting of relationships. New communications technologies mean that trust is no longer secured by “a firm handshake, getting the cut of someone’s jib”, and the social-ties forged through geographic proximity. “Trust knits society together, and makes it possible for people to get on with their everyday lives” (O’Hara and Hutton, 2004), and reciprocally that knit facilitates the formation and maintenance of trust.
Mayer et al (1995) define trust as “the willingness of a party to be vulnerable to the actions of another party based on the expectation that the other will perform a particular action important to the trustor, irrespective of the ability to monitor or control that other party.” The reference to vulnerability conveys that there is something important in the object of trust that could be lost should the trustee let down the trustor. The trustor risks a willingness to trust and determines whether to do so by assessment of the trustee’s trustworthiness.
When people trust one another, they have determined that their respective interests are encapsulated by the other; they’re aligned. The situation can be generalised (Hardin, 2002) as:
A trusts B to do X, optionally in context Y.
“To say I trust you in some way is to say nothing more than that I know or believe certain things about you – generally things about your incentives or other reasons to live up to my trust, to be trustworthy to me.” Hardin proposes that, rather than attempt to qualify or quantify a matter of trust, it’s far easier to account directly for trustworthiness, which then begets trust.
How trustworthy is our quotidien technology? The answer entails a longer and more challenging chain of trust.
To say …
A trusts T (the technology) to do X in context Y
requires that …
A trusts V (the technology vendor) in the context of both X and Y to develop, produce, and sometimes maintain and operate T according to V’s stated objectives and operating principles.
Trustworthiness is then trickier to ascertain:
- V is not a person but another legal entity such as a limited company absent any of the social traits A has evolved to recognise in the context of trustworthiness
- There is a distance in this relationship; A doesn’t meet V (more precisely, any person meaningfully representing V)
- There is no mutual agreement; V offers a contract of adhesion, typically reserving the right to change aspects of the contract at will
- V may not declare or make readily accessible its motivations and operating principles
- A can only ascertain V’s trustworthiness in developing, producing, and sometimes maintaining and operating T by intermediary expert E’s assessment, adding another link in the trust required
- With the intermingling of technologies, it’s not always obvious how to relate system behaviours to any given T, or indeed relate the T to any given V.
Ascertaining (un)trustworthiness requires a detailed technical examination beyond the means of many users of digital products and services. Absent knowledge of a reason to withhold it, and perhaps subject to prevailing norms (3.4.6), they offer their trust “irrespective of their ability to monitor or control that other party” (per Mayer et al., 1995).
Nudge is a mot du jour following the success of a book of that title discussing ways in which people might be influenced “to chose what is best for them” (Sunstein and Thaler, 2009). Unsurprisingly, much of the advice applies equally to marketers seeking to influence people to chose what is best for them. Metaphorically speaking a nudge might be said to be perceivable by the individual on the receiving end, yet such influence is not always perceivable and may be engineered deliberately not to be. Perhaps then it’s more accurate to talk of ‘being programmed’. “Very swiftly we lose control of many aspects in our life. The idea and trust that humans are very well capable of acting responsibly is slowly evaporating” (Christl and Spiekermann, 2016). In other words, if we can no longer trust ourselves because we’re unable to trust our technology, by corollary we become less trustworthy to others with corrosive consequences for the fabric of our societies.
This is not, I contend, a mere matter of public education, despite excellent efforts in that respect e.g. from the Wall Street Journal (“What They Know - Wsj.com,” 2010) and Public Radio (“Privacy Paradox from the Note to Self podcast, WNYC (New York Public Radio),” 2017). Personally speaking, despite having acquired this lens on the matter, I’m certain I cannot determine exactly when and how I’m being programmed, when and how my trust is being dishonoured. Just as importantly, and remarkably prescient given its time, Wiener (1950) observed our nature to “accept the superior dexterity of the machine-made decisions without too much inquiry as to the motives and principles behind these.” He warned that allowing a machine to make decisions for us – to “decide our conduct” – does not end well unless we do so having previously comprehended its calculus.
If we are then to trust technology and have that trust respected irrespective of our individual audit facilities, if our collective vulnerability isn’t to be suckered, we need to effect systemic change. Given that the mechanism exploiting our vulnerability is the data flowing unseen in the digital realm – data relating to our relationships, our proclivities, our movements, our transactions, our beliefs – grappling with the concept of privacy in the digital age is a good place to start. Yet before we can consider privacy, we must account for its subject.
3.3. Self-sovereign
This section helps us address two simple questions. Who are you? What are you?
3.3.1. Self-sovereign identity
Allen (2016) lists four broad phases of online identity models since the advent of the Internet:
Phase 1: Centralised identity (administrative control by a single authority or hierarchy)
E.g.: IANA’s domain over IP addresses, ICANN’s arbitration of domain names, certificate authorities (CAs) verifying ecommerce sites. As Allen points out, centralisation innately gives power to the centralised entities, not to the users. Despite there being four phases here, thiss phase still dominates.
Phase 2: Federated identity (administrative control by multiple, federated authorities)
E.g.: Microsoft Passport (1999), Liberty Alliance (2001). Allowed users to use the same identity for multiple websites and services. Passport placed Microsoft at the centre of the federation, whereas the Liberty Alliance was more oligarchical.
Phase 3: User-Centric Identity (individual or administrative control across multiple authorities without requiring a federation)
Pioneered by the Augmented Social Network and the Identity Commons, from which the Internet Identity Workshop6 (IIW) emerged. The IIW spawned a progression of user-centric identity protocols: OpenID (2005), OpenID 2.0 (2006), OpenID Connect (2014), OAuth (2010), and FIDO (2013). While these are decentralised, they can be co-opted and locked down by a centralising entity offering its users the convenience of ‘hosting’ their identity (e.g. Facebook Connect7). Allen contends such a manifestation is Phase 1 all over again but worse; more like a “state-controlled authentication of identity, except with a self-elected ‘rogue’ state.”
Phase 4: Self-Sovereign Identity (individual control across any number of authorities)
Rather than merely advocating user-centricity, self-sovereign identity requires it. This phase remains nascent.
Allen misattributes one of the first references to self-sovereign identity (the actual term then used was sovereign source authority) to developer Moxie Marlinspike rather than to the owner of The Moxy Tongue pseudonym, Devon Loffreto. Given that Loffreto had previously argued in favour of pseudonyms that cannot be connected easily by commercial social graphs such as Facebook’s (Loffreto, 2011), I cannot determine if Allen misattributed accidentally or ironically.
Loffreto (2012) defines sovereign source authority as “the actual default design parameter of Human identity, prior to the ‘registration’ process used to inaugurate participation in Society.” He contends that the societal registration of birth currently eliminates sovereign source authority and replaces it with an identity in society’s gift, asserting that this is a denial of the basic human right to self-declare participatory structure and authority; “Government is not formed to manage this process, but to be managed by this process.” As Windley (2016) puts it, “Descartes didn't say ‘I have a birth certificate, therefore, I am.’”
Loffreto (2016) defines self-sovereign identity in the following terms:
- It must emit from an individual human life (rather than society’s bureaucracy) and remain in the individual’s sole domain
- References every individual human identity as the origin of source authority; in the technical jargon, the individual has root authority
- Exists-in-waiting until the person takes control and authority, and mutually attests the identity with others (a form of web-of-trust)
- It may not exist in any given time or place, practically speaking, if the prevailing societal mechanisms do not accommodate it
- It may transmute via what I would call in our context here technological agencement (3.4.7).
There are a number of projects pursuing the realisation of self-sovereign identity including Consensys uPort8, Sovrin9, Blockstack ID10, and Namecoin11 ID. While development continues in parallel with self-sovereign technologies, it’s not easy to imagine the latter absent the former.
3.3.2. Self-sovereign technology
Their tech is out of our control (3.1). My tech is of limited value in isolation (4.2). Our tech entails us coming together as we each determine for our shared benefit.12 And as discussed (2.4.3), the “what are you?” is an agencement of “who are you?” and your technology.
In a world dominated by and saturated with their tech, it makes sense to first consider the opposite extreme, my tech. Moreover, our tech is more easily hewn from my tech concepts than their impenetrable and inaccessible tech.
The Internet Identity Workshop adopts the term self-sovereign technology and in its first attempt at a definition lists a number of components (Sheldrake, 2016a):
Policy assertions – The technology must be able to store and assert the owner’s policies (e.g. Do Not Track, VRM, User Managed Access (UMA) Authorization Server).
Authentication – Of the owner of the sovereign technology via a range of owner authentication methods (eg. a password, biometrics); (3.3.1).
Longitudinal notification endpoint – The technology should include a way to accept notifications from the services it interacts with and then follow the owner’s preset rules (e.g. alert the owner, modify the policies).
Non-repudiable link – To enable the sovereign technology to engage in non-repudiable (legally binding) transactions to the extent that the non-repudiable link is kept safely within the technology (e.g. biometric).
Whitelist of identity providers (IdPs) for requesting party (RqP) claims – A way to manage trust in the associated assertions.
Backup and recovery of the tech – Should be protected from loss or compromise.
Delegation – May be associated with a subject that is unable to operate technology (e.g. parents of a minor, children of incompetent parents); ownership is defined as the ability to take it offline or delete it.
Competence tests / partial delegation – May be associated with a subject that is only partially competent to operate it (e.g. younger children, some elders).
Filter for incoming data – Related to the notification endpoint above but broader, in the sense that any interaction with a sovereign technology may change its state.
Logging – Should provide a log of operation; may be private to the technology or public in order to meet trust and compliance requirements.
The hi:project is compatible with the concept of self-sovereign technology (4.3).
Having accounted for its subject, I can now review conceptual approaches to privacy.
3.4. Privacy and personal data
It sufficed for a time to define privacy as “the right to be let alone” (Warren and Brandeis, 1890). It endured for as long as it seemed that any individual might maintain some detachment from society’s gaze, an isolation constructed and construed from spatial and physical concepts by which one’s aloneness might be adjudged. My home. My room. My books. My letters. My car. My body and my personal space. Then new media added new dimensions for information flow and the ‘space’ was no longer so readily perceivable. This systemic change has catalysed deep and wide interest in defining privacy if only so we might articulate how it is altered by new technologies and applications, how it might or should be degraded, protected, or enhanced, and how we might qualify and substantiate any change as for better or worse.
The European Parliament defines personal data as any information relating to an identified or identifiable natural person (‘data subject’); an identifiable natural person is one who can be identified, directly or indirectly, in particular by reference to an identifier such as a name, an identification number, location data, an online identifier or to one or more factors specific to the physical, physiological, genetic, mental, economic, cultural or social identity of that natural person (EU General Data Protection Regulation, 2016).
I will return to the mixing of “data” and “information” in 4.2.
3.4.1. In disarray
Solove (2008) describes privacy as a concept in disarray, which is all the more problematic when the European Convention of Human Rights (1950) considers it sacrosanct.
Floridi (2005) identifies two popular theoretical approaches: the reductionist interpretation, whereby the goal is minimisation of the costs of privacy breaches; and the ownership interpretation, whereby informational privacy is elevated under the aegis of one’s rights to bodily security and property (i.e. the right to exclusive use). The first is criticised for its failure to grapple qualitatively with the societal costs of privacy (by corollary, the value of privacy ‘breach’). The latter has proved more durable both in terms of legal property and the right to exclusive use, as noted by the everyday spatial language above. Nevertheless, it is also inadequate, for example by failing to encompass:
- informational contamination, such as junkmail and loud and intrusive chatter
- public contexts (socially, physically and informationally) in which privacy norms still exist without any concept of ownership; e.g. the right not to have the contents of your packed lunch logged even though you eat it in plain sight
- lossless acquisition (or usage) – the fact that information can be reproduced without the individual losing it.
Solove refuses any attempt to pin a definition down succinctly, preferring to discuss a family of individually different concepts that are all related to our conception of privacy, collated and viewed ‘bottom-up’, deliberately adaptable to different attitudes found in different cultures, and focused on privacy problems rather than the concept of privacy itself. Despite the Convention, he concludes that privacy must be framed societally rather than as an individual right, specifically a society’s purview of information collection, information processing, information dissemination, and invasion.
Solove echoes Thomson’s (1975) proposition that the right to privacy is itself a cluster of rights, but not a distinct cluster. In other words, each of the rights in the cluster may be found in other clusters of rights; for example, being tortured to get information violates the right not to be harmed, and “spying on a man to get personal information is a violation of the right to privacy, and spying on a man for any reason is a violation of the right over the person, which is not identical with or included in (though it overlaps) the right to privacy.”
While writing two years before the Commodore PET debut – considered to be the first mass market personal computer – Thomson introduces the concept of information translations and flows that would emerge and grow rapidly with the advent of Internet connected PCs by imagining the use of technologies by individuals lacking one of the five senses; a deaf spy may read a transcript of an audio recording and a blind spy may feel a bas-relief of a photo. She concludes that such translations and flows are not pertinent to assessing whether there has or has not been a breach of privacy.
3.4.2. Contextual integrity
Nissenbaum (2004) also recognises the complexity of the concept of privacy and asserts that there is no need to construct a theory encompassing all the contexts in which privacy matters. Rather, she introduces the thesis of contextual integrity, that is “that in any given situation, a complaint that privacy has been violated is sound in the event that one or the other types of the informational norms has been transgressed.” Such norms vary from one context to another, from one society to another, and privacy is therefore a social construct rather than a fundamental right. Nissenbaum’s thesis is pragmatic, and while it carries no such citation it appears to expand on Thomson (1975): “If a man has a right that we shall not do such and such to him, then he has a right that we shall not do it to him in order to get personal information from him. And his right that we shall not do it to him in order to get personal information from him is included in both his right that we shall not do it to him, and (if doing it to him for this reason is violating his right to privacy) his right to privacy.”
3.4.3. Click to enable
Having reflected here on the difficulties of even defining privacy, it seems odd by comparison to consider the profusion of so-called privacy settings in software applications and web services (see an example in Figure 1). Such facilities cannot be mapped in any meaningful way to the concepts I have reviewed briefly here, rather these are broad-brush and typically binary settings permitting or disallowing various monitoring of and actions upon the data created in the very use of the application or service. There is a broad recognition – amongst law-makers, policy-makers and the information technology industry – that this gap must be closed, although some parties who consider themselves beneficiaries of the status quo disagree and continue to pull in the other direction, not least Internet Service Providers in the United States (Gustin, 2017).
The need for new approaches to shift the locus of agency and control back towards the consumer / citizen has been described as a grand challenge for contemporary computing in general and human-computer interaction (HCI) in particular (Crabtree and Mortier, 2016).

3.4.4. Metaphorically speaking
The current poor discernibility and control of our technologically mediated privacy contrasts almost beyond recognition with the philosophical deliberations, and bridging the two seems imperative; and just as bridge exemplifies, metaphor may aid comprehension and prompt engagement. Metaphor is renowned for providing clarity, and may also convey meaning more strikingly with the application of words taken out of ordinary usage. Moreover, done well, a pleasure of understanding follows the initial surprise and makes the abstract concrete (Ricoeur, 2003).
For these reasons, I’m drawn to this statement: “Privacy shelters dynamic, emergent subjectivity from the efforts of commercial and government actors to render individuals and communities fixed, transparent, and predictable. It protects the situated practices of boundary management through which the capacity for self-determination develops.” (Cohen, 2014; with reference to Altman, 1975)
Shelter – protect or shield from something harmful; prevent (someone) from having to do or face something difficult or unpleasant
I find shelter affective for the simple reason that I find myself increasingly engaged in conversations in which my interlocutors express feelings of over-exposure and tiredness from which they seek respite. Some refer to privacy and some do not. Nevertheless, metaphor can lose its impact with use, and talk of boundaries has peppered discussions of privacy for decades (Altman, 1975). The word immediately conjures spatial imagery but we’re very used to it in other contexts too now. Consider it in the context of these forms of privacy identified by O’Hara (2016): Privacy “can be epistemological (Bob shouldn’t acquire information about Alice), decisional (Bob shouldn’t interfere with Alice’s actions), spatial (Bob shouldn’t intrude into Alice’s space), ideological (Bob should tolerate Alice’s beliefs), and economic (Bob shouldn’t appropriate, use, or exchange Alice’s property).” Alice13 has boundaries. We know that. The metaphor is no longer striking and may then be losing its usefulness just at the point we need to valourise the privacy implications of unprecedented sociotechnical innovations. To quote Checkland’s regard for tired metaphors (1988): “Such words are so shop-soiled from use in casual everyday talk that they probably cannot now be purchased as technical terms.”
Floridi (2005) notes: “Analyses of privacy based on ‘ownership’ of an ‘information space’ are metaphorical twice over.” This exemplifies the ease with which metaphor might spawn mutually reinforcing metaphor, perhaps to the detriment of our broader understanding.
I am struck by Bratton’s use of columns (3.5.2), conveying as it does a tangibility, a direction, and a vertical spanning of architectural layers beyond physical reality as our interactions with other users form transient or more permanent columns up and down ‘The Stack’. Unlike boundaries it has no pre-digital metaphoric application in this context. And unlike shelter it doesn’t assume protection is always warranted (e.g. when reported for committing a crime).
I will return to the theme of metaphor.
3.4.5. Practically speaking
Christopher Allen is the co-author of the SSL standard (secure sockets layer – a network communications security protocol) and works specifically to frame privacy in ways that inform our design and development of digital architecture, software and services. In grappling with the variation in meaning for such practical purposes he differentiates four kinds of privacy (2015):
Defensive privacy
Defense against the intrusion of phishers, conmen, blackmailers, identity thieves, and organized crime, and also – while likely under very different context – governments. While quite possibly accompanied by some emotional and financial suffering, Allen notes an important characteristic of any corresponding loss of defensive privacy; it’s transitory and victims can “get back on their feet.”
Human rights privacy
Protection against existential threats resulting from information collection or theft, perpetrated by stalkers and other criminals as well as authoritarian governments. By way of contrast with defensive privacy, Allen observes that a human rights privacy breach entails long-lasting losses.
Personal privacy
The right to be let alone; protection against observation and intrusion. Allen describes it as being right at the heart of doing what we please in our homes and notes that a personal privacy breach can strip us of our right to be ourselves. It relates to disciplining control and self-modulation as discussed earlier (3.1).
Contextual privacy
Protection against unwanted intimacy, what Danah Boyd (2004) calls the “ickiness factor” – “the guttural reaction that makes you cringe, scrunch your nose or gasp ‘ick’ simply because there’s something slightly off, something disconcerting, something not socially right about an interaction.” When the ickiness factor comes to the fore, it’s likely attended by a feeling of exposure or vulnerability, of oneself or close others. It may come for example from a social network’s inappropriate intimacy, blurring the information defining otherwise deliberately distinct roles in life. A loss of contextual privacy allows another not to see you as yourself thereby endangering your relationship. For example, you may nurture a serious professional reputation and also enjoy a few beers and karaoke in your best Elvis get-up on a Saturday night. You may feel icky at the mere possibility of the latter emerging in the former context, let alone the actuality.
Allen’s four kinds of privacy offers a pragmatic way to consider the technological challenges of privacy, if only by conveying the variety to software architects and engineers in everyday language.
The Privacy By Design concept seeks to align engineers systematically to respecting privacy from the ground up (Cavoukian, 2011). It applies to IT systems, business practices, and physical design and network infrastructure, and consists of seven foundational principles:
- Proactive not reactive; preventative not remedial
- Privacy is the default setting
- Privacy embedded into design; it’s not an add-on
- Full functionality – positive-sum, not zero-sum
- End-to-end security – full lifecycle protection
- Visibility and transparency – keep it open
- Respect for user privacy – keep it user-centric
Privacy By Design has been endorsed by privacy regulators from around the world (“Resolution on Privacy by Design, the 32nd International Conference of Data Protection and Privacy Commissioners,” 2010). It’s preventative rather than curative, requires no input from any individual in question, and, per principle 6, operates according to the mantra trust but verify. In other words, it accepts that people trust “irrespective of their ability to monitor or control that other party” (per Mayer et al., 1995), but recognises that their trust is then more likely to be warranted if verification is in fact a possibility, by the user or more usually an independent third party. Application of the concept is known as privacy engineering: “an emerging research framework that focuses on designing, implementing, adapting, and evaluating theories, methods, techniques, and tools to systematically capture and address privacy issues in the development of sociotechnical systems” (Gürses and Alamo, 2016).
Privacy By Design enlarges the technical concerns beyond mere privacy settings, yet remains more heuristic than ontological. The following section assesses one such attempt to close this gap.
3.4.6. A bridge
In agreement with Solove and Nissenbaum, O’Hara (2017a) has observed that it would be hard, likely bordering on the impossible, to give necessary and sufficient conditions in defining privacy, and all the more so in an age of rapidly changing technologies (O’Hara and Shadbolt, 2008). He asks (2017a): “If we can discuss the state of (lack of) privacy independently of our claims to it, the rights associated with it, our preferences about it, our control over it, and the value of it, could we begin to make more sense?” He is pursuing a classic separation of concerns.
O’Hara starts by asserting that we are contemplating the boundaries of the self and group in instances where we talk in the first-person possessive; “my” and “our”. As language is informed by culture, it evidences our privacy norms accordingly, feeding back into the culture. In other words, both language and privacy norms are cultural, and as culture and language transmute mutually we can interpret our consideration of the boundaries of self and group linguistically. This approach has the advantage of adapting our conceptions for practical application as privacy norms evolve within any given culture, and from one culture to the next.
What is the boundary? How may it be described? Is it being crossed or transgressed? Is there interference with the interior? Is it subject to exterior attention? Each question may be framed relative to other agents, the use of specific adjectives, and for specific concepts of privacy, without any quality judgements implicit to the working definition of privacy.
O’Hara identifies seven interacting but distinct levels of concern:
Level 1: Concept
What concepts of privacy govern the relevant space / boundary? How do we adapt to new practices and technologies? And I would add, in what ways might we encourage them to adapt to us?
It takes privacy as a state and not a right, preference, norm, or legal concept, thereby keeping “separate the facts of privacy from our individual and social attitudes to it.” (2016)
Level 2: Actuality
Ask, is there an actual breach? This is different from there just being the potential for breach. O’Hara specifically dismisses responses framed in terms of other rights or laws (per Thomson and Nissenbaum above) at this level.
Level 3: Phenomenology
While a system’s opacity may leave you unaware of any breach of privacy, when it is apparent or becomes so, how does one feel? Shame? Disgust? Creeped out? Unbothered?
Level 4: Preferences
The individual articulates their preferred boundaries. When do I want to be (in)visible? Others also have preferences regarding the individual’s boundaries. What do others want of me? The final boundary is subject to negotiation and the range limits enforced by levels 5 and 6.
Level 5: Norms
The level at which Nissenbaum’s concept of contextual integrity comes into play. O’Hara notes Nissenbaum’s contention that when considering the digitalization of a process one should review the analogue norms that apply and carry them into the digital realm to preserve contextual integrity. I think this has a limited shelf-life however, if not already expired, as any such dilineation is increasingly dissolved.
Level 6: Law
O’Hara states that privacy is, unlike data protection, a cultural concept and not a legal one. Privacy law, as it exists from one jurisdiction to another, both codifies and informs culture. He recommends that law-makers seek to enable as many citizens as possible to satisfy their (level 4) preferences.
Level 7: Politics & morality
Reflecting on right and wrong, the nature of privacy rights, and political effects relating to democracy, security, autonomy, economics, and power.
O’Hara (2016) asserts that engineers – those charged with ensuring that technical and sociotechnical systems comply in privacy terms – and indeed everyone considering any aspect of privacy, must be clear at which level those terms and aspects are considered and articulated.
He also addresses the privacy paradox (Barnes, 2006) whereby individuals are seen to transgress their own preferences (level 4): “Perhaps people do adhere to particular norms at level 5, but their level 4 preferences are concerned with a whole Gestalt, crafted by system interface designers to affect them at level 3, involving much more than a simple experience of a privacy breach or otherwise. Any norm, including those of privacy, will be disregarded if the context makes it appropriate to do so.” Citing Deleuze (1992), Bratton (2015) goes further than attributing a certain artificial context from one interface to the next by describing the emergence of a new “control” structure, “for which anyone’s self-directed movements through open and closed spaces is governed in advance at every interfacial point of passage” algorithmically, an evolution “marked by the predominance of computational information technology as its signature apparatus.”
These observations prompt that we ask what level 5 and 7 deliberations might resolve to realise alternatives to level 3 designs and the motivations of their designers, or indeed spur level 6 intervention. (One noteworthy initiative, Time Well Spent14, is focused on pursuading level 3 designers to adopt what might be called a more ethical approach – discouraging design practices intended to get users to spend longer with and divulge more personal information through an app – aspiring it seems to effect change at levels 5 and 7 in the long-run.)
3.4.7. The individual at level 4
“Informational privacy requires [a] radical re-interpretation, one that takes into account the essentially informational nature of human beings and of their operations as informational social agents. Such re-interpretation is achieved by considering each person as constituted by his or her information, and hence by understanding a breach of one’s informational privacy as a form of aggression towards one’s personal identity” Floridi (2005).
In the context of O’Hara’s seven levels, Floridi has us contemplating “the individual” at Level 4 (Preferences) as an informational unit. He posits “you are your information”, with “no difference between one’s informational sphere and one’s personal identity,” thereby avoiding the first challenge to the ownership-based interpretation (informational contamination) under existing norms – “anything done to your information is done to you, not to your belongings.” What was previously a trespass of space becomes a kidnapping or unauthorised cloning, thereby circumventing the second challenge (public contexts) in which a trespass could not be claimed. The third and final challenge is rendered redundant when what was formerly my is now me, “a sense of constitutive belonging, not of external ownership.”
If this sounds a little odd Floridi points out the common term for the unauthorised and malicious acquisition of substantial personal information; identity theft. It is also supported by Heersmink’s cognitive theory research (2016). He concludes that personal identity must be seen as an environmentally-distributed and relational construct rather than merely a psychological or biological phenomenon. Heersmink quotes Clark (2007): “our best tools and technologies literally become us: the human self emerges as a ‘soft self’, a constantly negotiable collection of resources easily able to straddle and criss-cross the boundaries between biology and artifact.” And yet Clark also cautions that with such new modalities come new possibilities for coercion and subjugation. The sooner then that we redefine the individual at Level 4 the sooner we can re-project existing norms, law, politics, and morality.
Wiener anticipated this informational, cyber extension of ourselves (1950): “… where a man’s word goes, and where his power of perception goes, to that point his control and in a sense his physical existence is extended. To see and to give commands to the whole world is almost the same as being everywhere.” Two thirds of a century later it seems almost timid to define the individual here as an agencement being of the biological, psychological, informational, and interfacial (4). By being I do not deny the continuous ‘coming together’ nature of agencement but quite the opposite. I recognise that who I am is in constant flux. By being I incorporate the affordances of self-sovereign identity (3.3.1).
3.5. Agents in cyberspace
Wiener’s neologism, cybernetics, is derived from the Ancient Greek kybernētēs – steersman, governor, pilot, or rudder; apt for the study of regulatory systems. It’s recognised as the parent term for science fiction author William Gibson’s cyberspace (Strate, 1999). Strate acknowledges a wide variety of definitions, ranging from the futuristic and fantastical to the very real and present even as of 1992, insisting that it's best understood as the collective diverse experiences of space associated with computing and related technologies. I discuss a few ways of considering this space, always with agentic implications in mind.
3.5.1. Decentralisation
Aldous Huxley regarded the decentralisation of industry and government necessary for a better society (1937). Norbert Wiener’s insights into the dynamics and ethics of humans and large computer systems (1950) hinted at the advantages. Marshall McLuhan anticipated a shift from the centralized mechanical age to the decentralized electronic age, coining the term global village as shorthand for such a welcome outcome (1962). E.F. Schumacher considered decentralisation allied with freedom and one of “the truths revealed by nature’s living processes” (1973). Steven Levy’s hacker ethic includes the tenet “mistrust authority – promote decentralization” (1984). And Nicholas Negroponte (1995) regards decentralisation as one of the four cardinal virtues of the information society (alongside globalisation, harmonisation and empowerment).
A famous diagram by Paul Baran (1964), a prominent engineer in the development of the Internet, portrays the options:
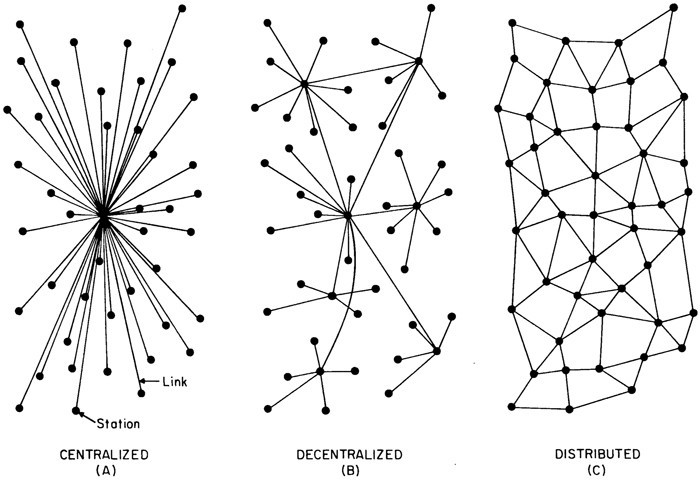
Distributed networks can better resist physical and digital attack because they have greater redundancy. Although Valdis Krebs, a leading authority in social and organizational network analysis, has yet to see a mapping of a real-world network that approaches Baran’s distributed idealisation, if one considers these three portrayals as sitting on a spectrum representing the leftmost, middle and rightmost positions, the pursuit of decentralisation is a journey rightwards (private communication, March 2017). Note that while decentralised is then midway between totally centralised and fully distributed, use of the verb to decentralise often describes that journey from left to right including progression right of the middle. The rallying cries of “decentralise!” and “redecentralise!” are more evocative than “distribute!”, and unless I’m comparing decentralised and distributed topologies, it’s how I employ the word.
The architectural manifestations of the Internet and the World Wide Web, both designed to be decentralised and distributed to varying degree according to the technical aspect in question, are drifting leftwards as network effects leave fewer and fewer organisations involved in the routing of data and the provision of software and services. A network effect describes the situation in which the utility and value of a product or service increases with the number of others using it. Although network effects in favour of proprietary products and services (as opposed to open protocols) leave corporate entities in positions of great power, it doesn’t follow that anyone is necessarily behaving badly. Unfortunately the consequence is a new invincible hegemony, freed from the market’s invisible hand (Ezrachi and Stucke, 2016); an aspirational position according to one Silicon Valley businessman who claims “competition is for losers” (Thiel, 2014).
Yet such centralised commercial power profits from assembling third actor agency for itself at the expense of its users (3.1) with the mechanics of Commercial Surveillance. I contend that Alice15 (the biological entity) has less agency today, in the digital age, without agency over her interface and personal data, than she would have had all other things being equal by her-biological-self in the pre-digital age. Furthermore, given that decentralized architecture is core to the very definitions of the Internet and the Web, to watch growing centralization is to witness their erosion (Sheldrake, 2016b), leaving us all losers. The deeper societal value of distributed architecture cannot be monetized directly by the market, so having benefited from a network that emerged beyond the market’s immediate concerns, market dynamics are now strangling it.
Having said that, I should clarify the mechanics of commercial decentralised architectures. Companies such as Uber16, a transportation network company, succeed by decentralising the points of purchase and service delivery. They’re classified as leaders of the so-called ‘sharing’ economy because they facilitate the efficient allocation of distributed resources to meet distributed needs. Their business model is extractive however, taking surplus rather than sharing it, and transactional control remains very much centralised as such extraction requires. A truly distributed competing network would be designed to realise mutual value, liberating surplus (Wistreich, 2015).
The degree of distributedness frees or constrains the perceived and actual value of participation, and frees or constrains the potential to participate. We can contrast diagrammatically the sociotechnical imbalance of centralised and centralising technology (Figure 3) and the balance afforded by distributed technologies (Figure 4), referring to the qualifiers my, our and their per 3.3.
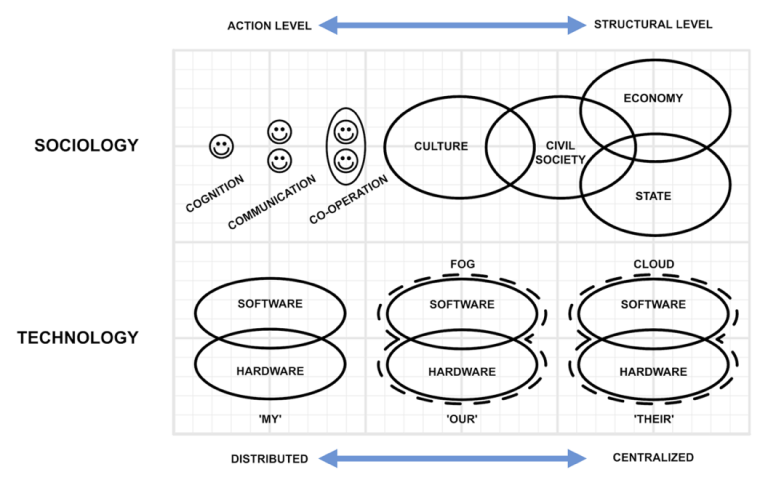
3.5.2. The Stack
Technologists refer to the layering of various technological protocols in varying integrative combination as a technology stack. As the topic here is the sociotechnical rather than merely technical, I’m drawn to Bratton’s six layers presented in his book The Stack (2015). His definition of each layer isn’t always as intuitive as the corresponding name might immediately imply, but this does not effect my portrayal here of the two layers susceptible to digital centralisation, Interface and Cloud (Figure 5). By way of example, Google’s Android OS commands 82% smartphone market share (Gartner, 2017), Facebook attracts 1.86 billion monthly active users as of end-2016 (“Company Info | Facebook Newsroom,” 2017), and Amazon’s cloud-computing business is reported to be larger in terms of basic computing services than the three closest competing offers combined (The Economist, 2017). The four (Amazon, Google, IBM and Microsoft) dominate the market, and even if companies such as Rackspace and Alibaba catch up, such massive technological realms constitute an aggregation more towards the centralized end of the spectrum (even if each company adopts distributed technical architectures internally).
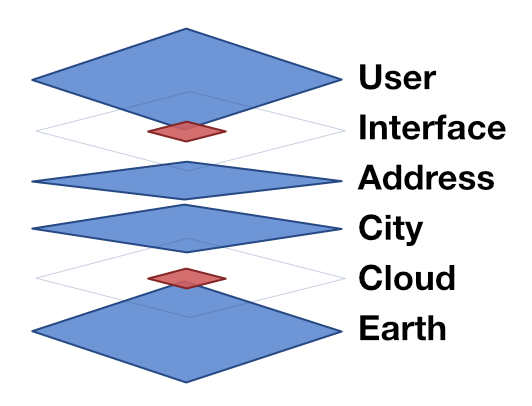
Bratton defines a column as a User to User connection following a U-shaped path or trajectory down from the User layer to the Earth layer and back up again. Figure 6 portrays three such paths. (I should note that Bratton adopts an expansive definition of User including humans, animals and purely technological agents, often referring to these occupying the User role.) Intuitively then, any constraints and controls exerted as a consequence of a centralising dynamic at the Interface and Cloud layers erodes personal agency – the number of paths available is constrained.

3.5.3. Skin
Defining the individual as an agencement being of the biological, psychological, informational, and interfacial, diffuses the individual’s being throughout the layers. Such presence isn’t encompassed by Bratton’s column and, as I concluded section 3.4.4, I’m now looking for a metaphor that does.
Skin is a candidate. It is well understood to encapsulate and demarcate the biological individual. It’s “my” per (O’Hara, 2017a). It grows with us. It’s protective and permeable and sensory. It is already adopted in mechanical engineering (e.g. the outermost structure of an aircraft), and software development (re. changing the ‘look and feel’ of a graphical user interface). Our skin is being considered an interface for interaction design (Liu et al., 2016). The concept of artificial or algorithmic skin is integral to aspects of quantified self by which “the mobility of data meets the mobility of bodies”, opening-up and closing-down bodily space (Beer, 2013). And it’s imagined that the world is acquiring a new skin of data (Thrift, 2014). I’m also drawn to phrases such as ‘get under someone’s skin’, implying information exchange, and ‘give someone skin’, denoting friendship and solidarity.
When we have the facility to understand, feel, and integrate the extension, presence, transience, and permeability of one’s skin, when we’re all sensitised to it, the legal definition of a person is reshaped and our norms revitalised accordingly (per 3.4.7). This marks the true manifestation of the sociotechnical agent. Data doubles of me are replaced by my digital doppelgänger, spawned and continually maintained by me, which in turn disappears, my informational space becoming me as much as my arms and legs and cognitive facilities. User interfaces disappear, the interfacial becoming me, prostheticizing me with the facility to understand and navigate the affordances of the world around me and those affordances denied (4.3).
Although it fails as a metaphor as far as a noemic eventuality is concerned, it suffices until such a moment and then perhaps in association, transforming the noemic manifestation in the process from one of “networked presence” to networked agency.
The mutuality, indeed the mutualism, of our tech (3.3.2) is integral to our existence and functioning as social animals, and permeability is perhaps the most important quality I’ve attributed skin. Skin accommodates the nesting and interpenetration of complex sociotechnical systems, in fact it is the very essence of such digitally mediated interactions.
This then questions the interdependent duality claimed by structuration theory for structure and agency (2.2), not because they might be distinct as Archer maintains but because any labelling of one or the other becomes entirely arbitrary. Regard for their duality always blurred the line but the agencement basis for skin and corresponding nesting at all scales renders the remaining allusion to scale redundant.
It also challenges Archer’s notion of ‘internal conversation’ as genuinely interior (2.3) in so much as our skin ‘interiors’ intermingle informationally, interfacially, and algorithmically. Moreover, the interfacial technologies at our disposal, as constituent elements of our skin (4.3), may have a machine learning based reflexivity rendering it agentic and structurally subjective in Archer’s context.
3.6. The Internetome
The more decentralised the fabrics of our society, the greater the opportunity one has to define one’s own skin, the less constrained one’s agency, and the more sustainable the living systems of which one is part. By definition, decentralisation demands decentralisation at every level, without exception for any exception would by definition be centralisation.
A stack implies some linearity that I believe can constrain perceptions and interpretations. My ‘stack’ is circular in nature (Figure 7). I call it Internetome, a repurposing of the name I gave an Internet of Things conference I designed and hosted in 2010. It incorporates the suffix -ome to describe the object of a biological field of study (e.g. genome, interactome, connectome, biome).
The vertex labels in red (excluding then instrumented non-digital and humans, i.e. in the biological sense) are explored briefly in the following sections in terms of the current qualities and characteristics that encourage or at least enable centralisation, and emerging innovations to attenuate this potential if not reverse it. I start however with the dotted lines representing consensus protocols.

3.6.1. Consensus protocols
Consensus protocols may be effective within and between any of the five non-physical vertices. The objective of such protocols is one of agreement whereby a number of distributed processes come to agree on a particular value after one or more of the processes has proposed what it should be (Coulouris et al., 2005). As one might interpret from considering this definition, such protocols are fundamental to the achievement of distributed technological architectures for without a method to secure agreement, centralisation is the only practical response.
A distributed ledger (also known as shared or public ledger) is one form of consensus protocol dedicated to incorruptibility, and the blockchain is one form of distributed ledger. The cryptocurrency Bitcoin pioneered the application of the blockchain approach in 2008, and the technology has been the subject of intense innovation subsequently, if only to secure some of the advantages of distributed architectures described here.
3.6.2. Digital devices vertex
Siemens and Ericsson used to make mobile phones. IBM and Sharp used to make PCs. Cisco and Sharp used to make video cameras. Hitachi and Philips used to make mp3 players. Sega and Atari used to make games consoles.
Nowadays smartphones serve many of these functions. Four manufacturers account for 51% of the global market and trending upwards and, as noted earlier, Google’s Android OS has 82% market share (Gartner, 2017).
There will be many factors impacting the consolidation of the consumer electronics sector beyond the scope of this work. The one that matters here is the product-service system – the close integration of hardware, software and services. The value flows with information flows, and information flows are managed by the software and services. As we’ve seen consolidation in software and services, the remaining profit margins in hardware demand massive volumes to maintain economic viability. This consolidation may only be reversed then by a reversal in the centralisation of proprietary software and services.
3.6.3. Post-TCP/IP networking vertex
Transport Control Protocol / Internet Protocol (TCP/IP), otherwise known as the Internet protocol suite, specifies how data should be packaged, addressed, dispatched, routed, and received. The suite consists of four layers, one of which, the internet layer, deals with the addressing of computing resources with the application of Internet Protocol addresses.
A World Wide Web domain name (e.g. southampton.ac.uk) identifies resources in a format that people can easily remember and each domain name is associated with a specific IP address (e.g. 152.78.118.52) so that the network can find the corresponding resources. A web address, otherwise known as a unique resource locator (URL), communicates exactly what is needed (e.g. southampton.ac.uk/uni-life.page).
Internet Protocol addresses denote a network location, and so do web addresses by association. The location of a digital resource also has a geographic location therefore, and a geographic location has politics. Whereas a web server in the 1990s was considered nothing more than a technological device, it may now be said to be German, Icelandic, or Canadian for example, communication with which is then subject to the prevailing law and state surveillance apparatus. From a Surveillance Capitalism perspective, the organisations providing one’s software and Internet services have the opportunity to profile one’s communications with various locations, aiding their construction of data doubles. The ‘dereferencing’ of domain names into IP addresses (the primary function of the domain name system) is considered problematic from the perspectives of centralisation, security, and privacy (Ramasubramanian and Sirer, 2005; Afanasyev et al., 2013; Internet Society, 2017).
Named data networking (also known as content-based or content-centric networking) encompasses techniques to address a resource based on what it is rather than where it is, eliminating the need for location data and therefore the problems described above (Zhang et al., 2014). It may assist the emergence of a ‘fog’ of distributed computing devices all around us in preference to a ‘cloud’ metaphorically and hierarchically centralised above us. Example projects include the Data Networking Consortium17, IPFS18, and MaidSafe19 (5).
3.6.4. Semantic vertex
The Semantic Web brings “structure to the meaningful content of Web pages, creating an environment where software agents roaming from page to page can readily carry out sophisticated tasks for users” (Berners-Lee et al., 2001). Assuming a future with distributed websites (i.e. centralisation is resisted elsewhere around the Internetome) the Semantic Web enables distributed sense-making, where sense-making is the process of finding a mental representation of a data collection in response to a particular problem or task (Russell et al., 1993). Absent semantic markup, the task of divining meaning remains deeply specialist (Google, 2012) and therefore more centralised than distributed. Understanding how meaning is inferred and having domain over sense-making technologies is considerably more agentic than subscribing to an opaque, centralised service entailing third actor agency.
3.6.5. Legal vertex
Law regulates behaviour with a system of rules; code. Similar effects may be achieved with software. Law may then be made more accessible, in terms of both ready availability and cost, rendered in software, although significant problems remain (Hillman and Rachlinski, 2001; O’Hara, 2017b).
Legal considerations are beyond the scope of this work.
3.6.6. Social vertex
“The web is already decentralized. The problem is the dominance of one search engine, one big social network, one Twitter for microblogging. We don’t have a technology problem, we have a social problem.” (Berners-Lee, as reported in the New York Times, Hardy, 2016)
I disagree. We don’t have a social problem. People are people, as the truism goes. Why for example would anyone wish to sever themselves from the comfort, convenience and connection of a centralized proprietary social network to join an open and decentralized alternative? They’d have to jump back on the proprietary social network just to let everyone know, which isn’t so much ironic as merely reflective of the network effect’s hold. Decentralization cannot be marketed. Marketing is based on the premise of benefit not burden (Sheldrake, 2016b).
Nevertheless, I share Berners-Lee’s attraction to distributed social networks, affording everyone complete, unmediated control of their social network, free of third actor agency, affording greater personal agency by definition. Decentralization might not be marketable, but if we know where the value lies for organizations and for individuals, we can design for decentralization to re-emerge in consequence.
Berners-Lee leads the Social Linked Data (SoLiD)20 project, a set of conventions and tools for building decentralized social applications based on Linked Data principles (Sambra et al., n.d.). Akasha21 is a distributed social network built on top of the Ethereum22 and IPFS platforms.
3.6.7. Interface vertex
This Internetome vertex is perhaps the one with greatest potential to effect redecentralisation and enhance agency.
Most obviously, the medium is the message (McLuhan, 1964). Or to put it round the other way, if you don’t own the interfacial medium, someone else does, in which case it’s their values and commercial motivations that get encoded not yours, and it’s your agency that’s corroded to their advantage. Defining an interface as “any point of contact between two complex systems that governs the conditions of exchange between these systems”, Bratton (2015) explores the computational prostheticization (an agencement) of user mobility and the corresponding reconfiguration and reprogramming of our urban space, noting the superior granularity and detail by which the interface can render the organisation of the urban space over the mere physical architectural reality (e.g. making walls transparent, helicopter views, general augmented reality). Ominously, he adds that this can be rendered differently for different users “according to different governing programs.” When the construction of Alice’s interface lies beyond her domain, Bratton observes that it’s the arbitrary precision of the interfacial diagrams that finally determines what a user can and cannot do; “… the governance is also the modulation and enforcement of the differential possibilities available through a specific interface and for a specific user.”
There’s good commercial reason Mark Zuckerberg believes the answer to some of our biggest problems today is more Facebook contrary to everything nature might have to teach us about centralisation (Zuckerberg, 2017).
Perhaps less obviously pertinent, today’s sociotechnical centralising behemoths all started out from this vertex. Google’s web search provided the interface to the Web, swiftly followed by mail, maps, Android, and the Chrome browser amongst others. Apple has focused relentlessly on the user experience, exemplified by the strapline accompanying the launch of the iPad: “you already know how to use it”. Ditto Facebook (both the interface and social vertices), Amazon (best shopping experience and the Fire OS fork of Android) and Microsoft (Windows, Office, and Bing web search). IBM is perhaps the notable exception on the edge of this elite group with its focus on commercial cloud and Watson AI services. It’s noteworthy however that Apple and IBM forged a global partnership in 2014 dedicated to enterprise mobility (Apple, 2014), rapidly expanding the following year into personal health based on Watson and Apple HealthKit (IBM, 2015). In co-operating, they’re better placed to compete with the others’ more extensive vertical integration, and indeed IBM considers partnering with those dominant at the interface vertex so critical that it is now also partnered with Microsoft for similar reasons (Weinberger, 2016).
As industry analyst Benedict Evans points out (2015): “it's the operating system itself that's the internet services platform, far more than the browser, and the platform is not neutral.” Witness the current ‘de-appification’ trend, where app use declines with the growth in conversational / messaging, bot-based and voice-activated interfaces (Pavlus, 2015) (Belsky, 2014) (Adams, 2014) – all of which fall under my definition of Surveillance Interface (4.3.2) – a development dominated by Apple’s Siri23, Google Assistant and Home24, Amazon’s Alexa and Echo25, Facebook’s Messenger Platform26, and Microsoft’s Cortana27. All these companies are OS vendors with the exception of Facebook.
In discussing the dynamics of such services, Bratton (2015) refers to the vendors connecting “oceanic reserves of information into smart services that learn as they are put to greater use” and, critically, observes that delivery is unlikely to be over the open Internet primarily but rather “through more narrowly designed and owned networks in which competitive advantages (drawn from physical infrastructure to data optimization to energy efficiency to format lock-in) will drive and delimit everyday computational economics.”
Centralisation starts at the interface vertex and works its way around the Internetome. For exactly the same reasons, decentralisation might best start here. Moreover, any architecture for redecentralisation that fails to address the interface may be hi-jacked at the interface by the dominant OS vendors and social networks. It’s reasonable to consider that decentralising innovations further round the Internetome (‘lower in the stack’) might not disrupt the centralising dominance of these companies so much as simply make this oligopoly appear all the more vital to users at the very point it all collapses down to the interfacial experience.
4. The interface
Tools change our capacity to act. Technology must always be a component of agency: Callon’s social agencement of human and technical devices; Ruppert’s observation that agency is mediated by particular sociotechnical agencement; Berg’s noting that one’s agency may be attenuated by a technological third actor; Barry’s framing of interactivity in terms of Foucauldian disciplining power; Zuboff’s disempowering surveillance; Hill’s and Lanier’s concern for dehumanisation; Couldry’s fracture of the space of discourse and erosion of direct human action and meaning-making.
As our lives become increasingly technologically mediated, any failure to limit the third actor agency accrued by dominant Internet and Web services leaves each of us, by definition, denuded.
Lash perhaps provided the segue to this chapter when he writes that we operate as interfaces and that interfaces are everywhere. Galloway (2012) concludes that an interface isn’t a thing per se, but rather an effect; “a process or a translation.” Similarly, Raskin (2000) directs our attention to actions: "The way you accomplish tasks with a product – what you do and how it responds – that's the interface."
4.1. Catering to difference
Here I note some human-computer interaction (HCI) concepts and frameworks each acknowledging to varying extent that one person and her context is different to another. As the title of a book on ergonomics puts it, it’s about fitting the task to the human (Grandjean and Kroemer, 1997).
4.1.1. Context
Schilit and Theimer (1994) first used the term context-aware to describe the user’s location, choice of device (“mobile and stationary objects”), those people and objects nearby, and changes to each of these over time. As information technology capabilities broadened and deepened through the remainder of the 1990s, the definitional scope broadened and deepened.
Abowd and Mynatt (2000) assert that a complete definition of context is illusive, offering up the “five W’s” as a minimal set of necessary context:
Who: the user and relevant others
What: perceiving and interpreting activity
Where: geographic location
When: timing and duration
Why: the most challenging of the five W’s to determine.
Dey et al (2001) defined context as “any information that can be used to characterize the situation of entities (i.e., whether a person, place, or object) that are considered relevant to the interaction between a user and an application, including the user and the application themselves. Context is typically the location, identity, and state of people, groups, and computational and physical objects.”
Here we must ask: considered relevant by whom or what, and with what purpose in mind?
Dourish (2004) notes the dual origin of context: a technical notion that helps system developers conceptualise the relationship between human action and the systems that support it; a social science notion describing social setting. He points out that the definitions are best approached from the very intellectual frames that give them meaning, recognising therefore that transdisciplinary application, such as our sociotechnical purview here, is challenging.
This conclusion is further evidenced by Bazire and Brézillon’s comparison (2005) of 150 different definitions of context across a variety of fields. While concluding that it’s difficult to identify one unifying definition, they assert that context acts like a set of constraints that influence the behaviour of a system (a user or a machine) embedded in a given task. The reference to constraints is reminiscent of sociologists’ early regard for structure, only latterly considering structure enabling as well as constraining. Yet this analysis of the nature of context cannot encompass the possibility of context being enabling as the absence of constraint is to be taken as an absence of context.
These definitional conclusions remain unchallenged more than a decade later. Perera et al (2014) for example reference both Abowd and Mynatt, and Dey et al, in considering context aware computing for the Internet of Things, selecting the former as their working definition.
Nevertheless, the W3C Model-Based User Interfaces (UI) Incubator Group considered Dey et al’s definition “rather general” and “not directly operational” (Model-Based UI XG Final Report, 2010). For example, when Nissenbaum (2004) refers to the contextual integrity of privacy, she conveys that there is no facet of life not subject to norms of information flow. At no point, in no place, in no circumstance, does ‘anything go’. Rather, everything occurs in the context of place, politics, convention, and cultural expectation.
Intent on being more specific in the domain of interactive systems, the Group’s report highlights the CAMELEON (Context Aware Modelling for Enabling and Leveraging Effective interactiON) Unified Reference Framework (Calvary et al., 2002), intent as it is on defining ‘context of use’ as a dynamic, structured information space that includes the following entities:
- U – a model of the user (who is intended to use or is using the system)
- P – the hardware-software platform (which includes the set of computing, sensing, communication, and interaction resources that bind together the physical environment with the digital world)
- E – the social and physical environment (where the interaction is taking place).
The framework is informed by Coutaz and Rey’s (2002) endeavour to establish a more specific and more useful ‘context of interaction’ in which the user and the task are given primacy, and where particular effort is made to understand changes to the situational context over time.
4.1.1.1. Separation
It’s noteworthy that none of this work grapples directly with agencement – the assemblage of human and technology as one. The contextual who (the user and relevant others) remains distinct from the contextual what and where; the object, the device, the data, the system, the place, the space. This state of affairs may be attributable to the well-established software engineering principle known as separation of concerns, adopted as Hürsch and Lopes (1995) explain to make software easier to write, understand, reuse, and modify. Relating to our topic here, they identify algorithm, data organization, process synchronization, location control, and real-time constraints as separate concerns.
4.1.2. CC/PP and ARIA
CC/PP (Composite Capability / Preference Profiles) describe device capabilities and user preferences. The former is sometimes referred to as the device’s delivery context, guiding the adaptation of content for presentation on the device (“W3C CC/PP 1.0,” 2004).
The corresponding W3C working group, Device Independence, focused primarily on device capabilities and configuration rather than user preferences. Outstanding items relating to the device work were completed under the auspices of the Ubiquitous Web Applications working group, disbanded July 2010. The W3C Web Accessibility Initiative took on the CC/PP specification from the accessibility perspective, although progression of ARIA has taken priority.
ARIA (Accessible Rich Internet Applications) employs semantic information about interface components (widgets, structures, behaviours) and user-modelling of the individual’s needs to better enable the tailored rendering of interfaces to persons with disabilities (“Accessible Rich Internet Applications (WAI-ARIA) 1.0,” 2014, “User Modeling for Accessibility Online Symposium,” 2013).
In their study of Rich Internet Applications (RIA) research over a ten year period to 2011, Castelyn et al (2014) note a remarkable growing trend in the application topic of “usability & accessibility”, but point out that the vast majority of this research growth entailed accessibility rather than usability. The authors observe that the topic “adaptivity, personalization & contextualization” received relatively little attention, peaking in 2009.
4.1.3. Model-based UI
Model-based UI design is a deliberate framework for and process to differentiate different levels of design concerns, adhering to the separation of concerns principle. Designers are then free to consider one level of abstraction at a time, focusing on more important aspects without the distraction of implementation complexities (“Introduction to Model-Based User Interfaces,” 2014). A model in this context is any representation of a real or imagined aspect of an interactive software for the purpose of UI development (“MBUI - Glossary,” 2014).
Model-based approaches were popularised in response to the proliferation of mobile devices, and therefore device delivery contexts, in the first decade of the century (e.g. TERESA, USIXML, UIML). The corresponding W3C incubator group concluded in 2010 (Model-Based UI XG Final Report, 2010). The follow-on working group (MBUI WG) updated some specifications, and closed with the publication in 2014 of an introductory guide (above) identifying the CAMELEON (referenced in 4.1.1 above) reference framework (CRF) as the widely-accepted reference for structuring and classifying model-based development processes.
The CRF has four levels of model abstraction:
- The task and domain models – the hierarchies and sequence of tasks that need to be performed on/with domain objects to achieve the users’ goals
- The abstract UI (AUI) – independent of modality (e.g. graphical, vocal, and gestural) and implementation technology
- The concrete UI (CUI) – modality dependent, technology independent
- The final UI (FUI) – modality and implementation technology dependent.
The benefits of model based UI development reported by the MBUI WG include: supporting UI quality factors such as usability, accessibility, completeness, consistency and correctness; enabling the production and comparison of alternative designs for multiple contexts of use while preserving quality; explaining and justifying the UI to the end user; enabling UI evolution by the user and by the system.
4.1.4. Service-oriented / Semantic UI
Model-based approaches are developing to work with and take advantage of Web services architecture, facilitating a complete abstraction of the function from the presentation; for example, the model-based language MARIA (Paterno’ et al., 2010).
He et al (2008) describe an adaptive user interface generation framework for web services based on web services description language (WSDL). The framework intends to automate the development of graphical user interfaces to suit varying uses and user devices.
A semantic UI enables interaction with the semantic web (also known as the web of data, see 3.6.4) in a more contextually specific manner than a semantic browser.
4.1.5. Distributed UI (DUI) and liquid software
Melchior et al (2009) describe a DUI as a multi-purpose, peer-to-peer proxy that can render a UI for any user, operating system, platform and/or display. Elmqvist (2011a) expands this definition to those UIs “whose components are distributed across one or more of the dimensions input, output, platform, space, and time.” Kovachev et al (2013) explore the ‘widgetization’ of DUI.
Mikkonen et al (2015) conceive liquid software – the facility to make a user’s heterogeneous devices work better together with interaction moving seamlessly and contextually between them.
4.1.6. Interaction-Oriented Software Engineering (IOSE)
Software engineering is machine oriented for specified sociotechnical system (STS) requirements, and while the resultant machine may be architecturally distributed, it is conceptually monolithic (Chopra and Singh, 2016; citing Lamsweerde, 2009).
IOSE places the emphasis on the STS, focusing on social protocols rather than implementation, specifying how social relationships progress as parties interact, and analysing each party’s autonomy and accountability in particular. It entails parties invoking their own machine to help them participate within the corresponding social protocol. Chopra and Singh assert that failure to do so limits user autonomy.
4.2. Human-Data Interaction
Human-Data Interaction (HDI) is the study of the interactions between companies and individuals engaging in the use of personal data. It encompasses the interactions between humans, data, and the algorithms used to analyse and interpret the data (Mortier et al., 2013, 2014). Mortier et al claim it to be distinct from Human-Computer Interaction (HCI) in that HDI does not focus on human interactions with computer systems, but rather three core themes or principles:
Legibility – making data and analytic algorithms transparent and comprehensible to users
Agency – the facilities to manage relevant data and access to it as and when the user sees fit
Negotiability – addressing the many social aspects that arise from and around data and data processing.
Elmqvist (2011b) defines HDI as “the human manipulation, analysis, and sensemaking of large, unstructured, and complex datasets”, blurring HDI with interface design because the nature of the interface remains an essential consideration.
HDI has also been defined in terms of “delivering personalised, context-aware, and understandable data from big datasets” (Cafaro, 2012).
HDI is closely related to the personal data store (PDS) concept, one example being the Databox (Mortier et al., 2016): a collection of physical and cloud-hosted software components that provide for an individual data subject to manage, log and audit access to their data by other parties. This log and management facility is designed for a new kind of economic actor, active rather than passive, directing instead of being directed by the emerging data economy (Crabtree et al., 2016).
Yet data of itself is just discrete, objective facts representing the properties of objects and events. Data is the lifeblood of computers, but humans do not readily work with data. Rather, we deal in information; that is processed data, data made useful, data made relevant (Ackoff, 1989). Cafaro’s “understandable data” appears then a contradiction in terms requiring the intermediary processing of data into information. Unfortunately, the European Parliament defines personal data in informational terms, completely blurring the distinction (3.4), but I maintain the distinction here qualified by Ackoff.
The following statement exemplifies two significant problems of personal data:
You used 400kWh of electricity last month28.
The first problem relates to the pronoun; is that you Alice29, or you Alice’s household? It turns out that much data we consider personal is actually data we share with others, merely reflecting our social nature. Your lunch appointment is data shared with your lunch companion. Mortgage payments may be shared with a spouse. Some rights over a video you’re in may be shared with others featured similarly. It might be your bus journey but the bus company will want to know how many are aboard for its ongoing capacity planning. It might be your immunisation, but those responsible for public health will want to ascertain herd immunity. It might then be more accurate to talk of personally and socially material data.
The second problem relates to the datapoint insomuch as it’s unclear exactly what anyone might do with it; for the example of household energy use, perhaps one might compare it to the previous month or the same month in previous years if the seasons have any bearing on energy use. Even when a difference is determined, is this a change in household energy efficiency, or the weather, or your weekly schedule?
Personal data must be allowed to breathe for it to be of most value to the individual and society (Sheldrake, 2014), by which I mean (a) the context of similar datasets is needed for the useful transformation of personal data into personal information to assist Alice’s comprehension and sense-making, and (b) there may be societal value in Alice’s data aiding our collective comprehension and sense-making of populations, whilst preserving personal privacy.
In terms of the example here, whereas the datapoint is 400kWh, the information may be:
Your household used 10% less energy in April this year than last year, although half of that difference is because the weather was slightly warmer and you weren’t at home so much; three out of five households of a similar size and occupancy to yours in your area used more energy, so you’re above average but with room for improvement.
Note that the data is rendered into information – into valuable, actional insight – when data flows in combination. Flow does not require static facsimile. Combination does not require uncombined facsimile. Moreover, facsimile will by definition never be master. I contend therefore that Alice does not need a personal data store, rather insight into where personal data is flowing and for what purposes, entailing an interface into and onto the permissions and flows, constituting Alice’s skin and by definition her awareness of it (3.4.7 and 4.3). Furthermore, skin is simultaneously my tech (hence “Alice’s”) and our tech per personally and socially material data.
Agency is the potential to influence. To influence is to make a difference. Information is a difference that makes a difference (Bateson, 1972). Data only effects agency indirectly via its interfacial transformation and so the interface had better be sovereign (3.3.2).
4.3. The human interface and the hi:project
The USB Forum has a working group called Human Interface Device (HID)30. Guidelines for developing application and device user interfaces (UI) and experiences (UX) are sometimes known as Human Interface Guidelines (HIG), and Apple may have been the first to publish such guidance (Apple Human Interface Guidelines, 1987).
This section is dedicated to the human interface as defined by the non-profit hi:project31. I started the project in 2012 and regular contributors in recent years include Steve Taylor, Christina Bowen, Jeremy Ruston, Adrian Gropper, Ian Brown, Laura James, and John Laprise.
4.3.1. The project’s purpose
“The ultimate information technology challenge is the care and maintenance of a digital infrastructure that can help us rise up to so-called super wicked problems, collectively. Given the growing appreciation of the nature of complexity and the complexity of nature, we know we’re in the domain of systems thinking and sustainability – the health and resilience of living systems including our planet, our societies, and our organisations.
… Sustainability requires healthy, distributed networks, with both diversity and individual agency, to facilitate the emergence of collective intelligence. It is these qualities our digital technologies must enable and encourage.” (Sheldrake, 2015a).
4.3.2. The hi:project – nomenclature and definition
The human interface project (the hi:project) describes an HCI concept and a supporting team intent on bringing the concept to life and securing broad participation. The term human interface was chosen32 to be distinct from the more common term user interface33 and yet remain sufficiently familiar. The nomenclature is intended to convey different attitudes towards the individual concerned.
While user means a person who uses or operates something, it’s not entirely irrelevant to note that the word also describes a drug addict and might even connote exploitation. In the context of UI, a user is a customer (payment in currency or in kind, directly or indirectly) viewed by the product supplier through the lens of the product. While the organisation may aspire to put the customer first, so to speak, it only does so within its own realm. For example, as noted in 3.1, as products are replaced by product service systems, any commercial imperative to secure ongoing monetization potentially puts the service provider’s needs in competition with those of the user. You might wish to explore your LinkedIn social graph extensively for example, but as such facility would undermine LinkedIn’s monetization of the social network you are restricted to using its UI through which your queries are restricted.
In contrast, HI unequivocally gives unassailable pre-eminence to the individual / the person / the human, and the corresponding idea of human-centricity is then more expansive and more potent than user-centricity, encompassing the full gamut of human life and agency rather than domain-specific services with otherwise unavoidable third actor agency.
I divide Raskin’s (2000) definition of the interface into three types.
The Interface: The way you accomplish tasks with a product – what you do and how it responds – that’s the interface.
The UI: The way a machine or service helps you accomplish tasks with or through it, that’s the user interface.
The SI: The way a machine or service surveils, records, interprets and to some degree controls your life to help you accomplish tasks with or through it, for the direct or indirect profit of the service provider, that’s the surveillance interface.
The HI: The way your software helps you accomplish tasks with other software, that’s the human interface.
Taxonomically, the SI is a form of UI. However, I tend to consider them as qualitatively distinct for the simple reason that they ‘feel’ qualitatively different to the user, and are architectually very different on the back-end in the very way that Berg (2012) distinguishes the corresponding individual-oriented and system-oriented agency.
It would be both confusing and inappropriate to call the individual served by HI the user, and simply substituting human in the singular sounds too detached and frankly somewhat odd. Therefore, I adopt the placeholder name Alice34.
The UI and SI are wed to the end- or intermediate machine or service, and their day-to-day function and periodic updates remain under the vendor’s control. In some jurisdictions, protected by what many see as the misapplication of copyright law, ownership of a product dependent on software for its operation does not encompass ownership of that software, just its atoms. The requisite software remains the vendor’s property (Walsh, 2015).
The HI belongs to Alice. It supports many of the attributes scoped by attendees of the 22nd Internet Identity Workshop to describe sovereign technology and does not detract from the others (3.3). Simultaneously, Alice has a digital self and a self with digital presence. Simultaneously, her HI is her and it is her representative, her agent. Simultaneously, it is core to her agency and must be subject to it.
4.3.3. Adaption
According to Raskin (2000) “an interface is humane if it is responsive to human needs and considerate of human frailties. If you want to create a humane interface, you must have an understanding of the relevant information on how both humans and machines operate.”
Bratton (2015) points to the maxim “If you can’t open it, you don’t own it,” adding that systems that can be redesigned by the user are both more resilient and more accountable. Agency encompasses redesignability.
Traditionally, the user is required to adapt to the UI. We all have different digital, numerical, information and visual literacy, and many people have one or more disabilities, yet UI/UX designers cannot cater to this variety (“The hi:project website homepage,” 2016). Some of the interface concepts described in brief earlier collect user information describing such differences and then customise the UI to better meet the user’s needs. The product / service provider controls the type of user information collected and the bases by which that information is used to select from the options available, the variety of which may be constrained by cost-benefit analysis.
In contrast, HI adapts the data exchange, its presentation and the interaction with the machine or service to Alice’s needs. HI can aspire in the longer-term to be ‘just right’. Alice’s HI software exists to personalise her interface and will, subject to establishing a corresponding broad and deep ecosystem (4.3.6), be able to call on a massively more diverse set of components to achieve this goal, under her control.
HI not only adapts to Alice but with Alice. As Doc Searls of ProjectVRM and the Berkman Center for Internet & Society points out: “We’re all human. We’re also all now on one worldwide network, and we need to keep that human too. Nothing is more human than our differences — not only from each other, but from our former selves, even from moment to moment and context to context.” (“The hi:project: Champions,” 2016).
4.3.4. The technology
As Web of Data35 developments decouple the app from the data, the hi:project decouples the interface from the app (Sambra and Sheldrake, 2015). The hi:project re-imagines the interface as a lightweight artefact that can be shared within a community-based ecosystem. Participants are able to freely copy, modify and share improved or customised components, distributed and discoverable across a named data network architecture36 such as those proposed and developed by the Named Data Networking Consortium37, IPFS38, and MaidSAFE39, with provenance recorded in distributed ledger (3.6.1).
Figure 8 portrays the construction of Alice’s HI. The collection of devices / environments bottom left represent a ‘fog’ distributed around us as opposed to today’s cloud centralised above us.
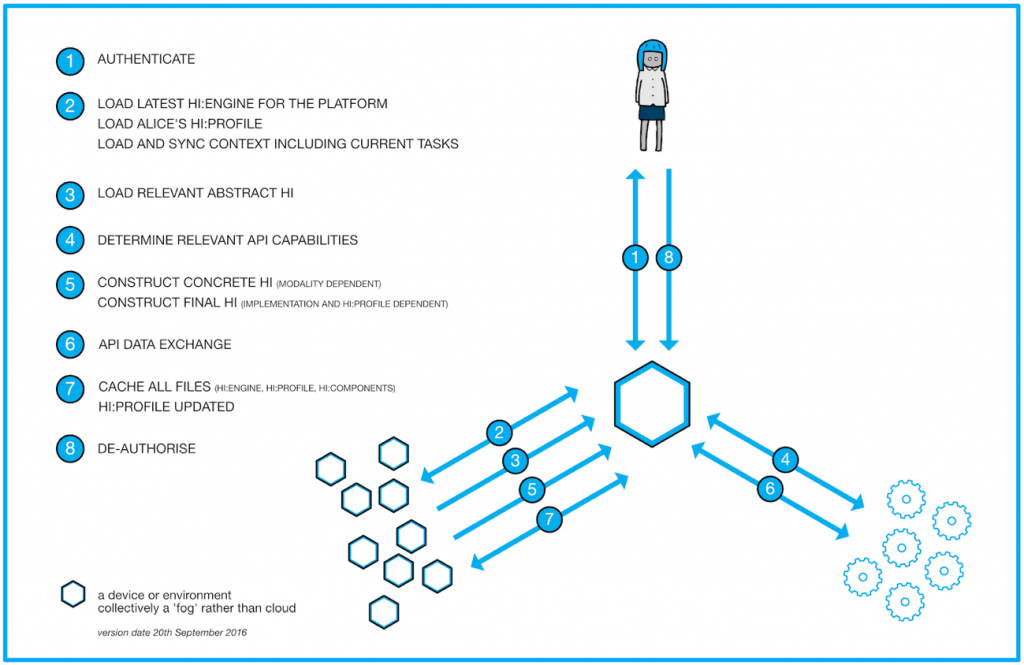
The following sections outline the hi:framework, the hi:engine, the hi:profile, the hi:components, the hi:ontology, the hi:cache, and hi:coin. The project’s designs and technology are free and open source.
4.3.4.1. The hi:framework
The hi:framework details the hi:engine’s dynamics in terms of identifying service types, specifying APIs, determining how to personalize the HI, the collation and maintenance of the corresponding personalization data, and how this may then be wielded in selecting and assembling the hi:components available to it.
The hi:framework will be informed by existing model-based UI concepts – including abstract, concrete and final HI – and will address three levels of interface. Provider HI replaces a service provider’s UI. Service HI spans data describing Alice’s relationships with multiple service providers of the same ilk; a number of retail banks for example. The life facet HI enables Alice to review and interact with her life in the round, spanning services; her complete financial situation for example by combining data relating to banks, credit card issuers, mortgage providers, cryptocurrencies etc.
The framework will articulate a personal privacy profile to inform others how personal data should be treated in compliance with local regulations and personal preferences (Sheldrake, 2015b).
4.3.4.2. The hi:engine
The hi:engine is Alice’s personal software platform that assembles her personalised interface. (The way your software helps you accomplish tasks with other software, that’s the human interface.) It reads and writes to her hi:profile, calling the appropriate hi:components as needed contextually for Alice’s interaction purposes. It also maintains and communicates her privacy profile.
The hi:engine needs to learn from Alice, explicitly and implicitly. The simplest learning capability might be considered sufficient to render a HI experience superior to the UI equivalent, and such capability falls short of anything anyone might describe as artificial intelligence (AI). The hi:project does not aim to develop AI capabilities yet will explore the potential for integrating AI software and services developed by others to enhance the HI experience. The hi:project may, for example, be the ‘Open Interaction’ partner to OpenAI40.
As and when service providers’ application programming interfaces (APIs) migrate to Linked Data format (and perhaps the hi:project might encourage such a transition), the hi:engine may act, less contextually, as a personal and personalised semantic web browser.
The hi:project does not aim to develop new approaches to personal identity and authentication; it is agnostic in this regard, enabling Alice to select her preferred approach(es) / service(s).
The hi:project is agnostic in terms of personal data stores. It will interoperate with such products and services, but stores are less relevant when personal data are available from source near instantly for personalised combination, presentation and interaction. Some storage facility may be pertinent with respect to data portability (changing service providers), and data backup will alleviate the disruption otherwise caused by the unexpected cessation of a service for whatever reason.
4.3.4.3. The hi:profile
Alice’s hi:profile informs the assembly of her HI in the moment. It is available and synchronised across platform / device / environment, and is subject to constant revision in terms of:
- Customization – the explicit statement of preferences (“I prefer …”)
- Crowd – learning from collective behaviours (“People who … prefer …”)
- Segmentation – identifying similarities between individuals (“People like you …”)
- Personal – implicit, interpreting the individual’s specific proclivities.
Pooling hi:profiles to enable such statistical analyses will be subject to the same privacy preserving techniques as for other personal data (4.3.5.1).
4.3.4.4. The hi:components
The materials the hi:engine works with: data and information models; graphical libraries; methods for adapting information appropriate to the topic, the individual, medium and context. The components will likely follow the model-based UI distinctions of abstract, concrete and final interface.
4.3.4.5. The hi:ontology
The hi:components and hi:profile will be described semantically, for optimal distribution and discovery in the case of the former.
4.3.4.6. The hi:cache
The cache of commonly used components, for reduced latency and for mesh / named data network availability.
4.3.4.7. The hi:coin
Depending on the parameters of the technology adoption model, a cryptocurrency (hi:coin) may prove useful. Coin would flow from companies and other organized entities to Alice by way of payment for access to her HI (and potentially her personal data), and from Alice to developers by way of design bounties, and from developers to companies by way of developer remuneration in fiat currency.
4.3.5. The objectives
The hi:project aims to help: solve personal data and privacy; secure a citizen-centric Internet and Web; and transform accessibility and digital inclusion. Each objective benefits agency. Ultimately, the hi:project is a sociotechnical cornerstone of skin (3.5.3).
4.3.5.1. Personal data and privacy
The interface is the locus of Alice’s data / information and the nexus of her contextual privacy parameters (Sheldrake, 2015c). By having domain over her interface, by exchanging only that data directly related to the provision of a service (e.g. HI has no need for third party cookies), in being explicit about her privacy expectations, and by adopting end-to-end encryption, Alice has improved domain over her personal data and privacy. With that capability and confidence comes greater facility to ‘act otherwise’.
The project aims to facilitate meaningful (as opposed to ‘tickbox’) compliance with personal data legislation such as (EU General Data Protection Regulation, 2016).
4.3.5.2. Citizen-centric / redecentralised Internet and Web
HI is, by its very definition, a distributed architecture. Nothing like it can exist in any other way.
As noted earlier: distributed architecture has no point of centralisation, of mediation, of control, including then the presentation and interaction layer / the interface vertex; and centralisation is best challenged from the interface vertex as it’s the foundation of the centralisers’ hegemonic power (3.6.7). HI may, for example, be the perfect Trojan horse for SoLiD41 as APIs are harmonized by sector and service, perhaps gravitating towards a linked data platform design (Sheldrake, 2015d).
With HI, Alice has ‘sight’ of any governing program so designed and the facility to adopt, adapt, or indeed reject it accordingly. She should ‘see’ any constraints placed by others, directly or indirectly, on a thing’s / a system’s facility and readiness to interact. Whereas the default trajectory for the Internet of Things today appears to be an ‘Internet of Their Things’, with HI, “everything gets an interface when the citizen brings her own” (Sheldrake, 2015b). Should Alice be attracted to the phenomenal capabilities of conversational bots manifest today as surveillance interfaces (4.3.2), she can now situate them as services to be selected and controlled – “expertise is supplied rather than outsourced” (Lukas, 2014) – thereby attenuating their third actor agency to the accretion of her own.
4.3.5.3. Accessibility and digital inclusion
“As with race, gender, and sexual orientation, we are in the midst of a grand re-examination. … disability may turn out to be the identity that links other identities …” (Davis, 2002). This new era “ushers in the concept that difference is what all of us have in common. That identity is not fixed but malleable. That technology is not separate but part of the body. That dependence, not individual independence, is the rule.”
Davis proposes a new guiding principle: Form follows dysfunction.
HI doesn’t “cater to” or “accommodate”. HI doesn’t need to include anyone because it never excluded anyone. HI is simply informed. The HI form follows our differences and encourages us to explore our differences, together. If agency is “socially and differentially produced” (Barker, 2007), perhaps then its distribution might become more even.
4.3.6. The business case for dissemination
HI will be seeded with people through the organisations that feature in their digital lives, likely starting with business-to-consumer relationships. The commercial benefit to these organisations takes two forms.
First, HI is a superior experience to UI. It’s respectful of Alice. It builds participation, trust and loyalty, and secures market differentiation for the earlier adopters. It entails no capital expenditure and lower operating expenses. It assists with legal compliance, and switching costs are expected to be less than an iteration of current UI.
Second, commercial value in a data-oriented relationship does not come from the data per se but from its contextual and permitted translation into actionable insight. Cross-domain data aggregation is required to determine this context, and the dominant OS vendors and social networks have no rivals in this regard. Nor are they rivalled in terms of their ability to offer associated permission management. This very small group of players then has substantial commercial power acting as data flow tollgates.
Google generated average revenue per user (ARPU) of US$45 in 2014 (Meeker, 2014), predominantly from its surveillance of web and app use for advertising purposes. We might assume that the value of the data describing Alice’s continuous interactions with a pervasive computing environment will be just as valuable to a toll keeper, and quite possibly more so.
HI disintermediates and decentralises cross-domain contextualising and permissions management, eliminating such mediation and related toll fees. Further, significant operational risk is removed for all providers of services dependent upon these data flows; absent HI, all incumbents have no choice but to proceed on the basis that one or more mobile OS vendor / tollgate operator may decide to compete directly at any moment, and with unmatchable advantage.
4.3.7. Next steps
The hi:project is designed to gain momentum with momentum; a diverse and distributed community of multi-disciplinary experts, organisations, and Alice, exploring and designing for our differences together. We expect Alice to show purchasing preference for those organisations marketing their participation in and support for HI.
To get to that stage we need to develop the first versions of the hi:framework and hi:engine, and likely the first core components for a provider HI experience in a specific sector as proof of concept, eg, retail banking42. The project team is pursuing a number of funding options: commercial sponsorship based on the associated business case (4.3.6); grant-making foundations interested in decentralisation or digital inclusion; forming a member-funded co-operative to invest in sovereign tech43.[Page]
5. The ecosystem for networked agency
Section 4.3 focused on one project focused on the one Internetome vertex. As noted in section 3.6, decentralisation demands decentralisation at every level, at every vertex, without exception for any exception would by definition be centralisation. I have then begun to seek out, research, and map the ecosystem of organisations and projects developing concepts, products and services that might maintain or improve personal agency, at least relative to the centralised and centralising alternatives.
The mapping work is exploratory and it’s not yet clear what may be learned or then how this may be useful to the ecosystem itself. Clearly, the potential analyses are informed by the data collected and I’m in correspondence with many participants to determine how this may be extended usefully.
5.1. Mapping the ecosystem
Given the tenuous commercial situation, it’s not surprising that the majority of initiatives are run by informal project groups rather than being hosted by more formal organisations. At this stage, the map consists 115 projects and 15 organisations, and it is currently hosted at:
https://kumu.io/DigitalLife/digital-life-collective44
Kumu is described as a powerful data visualization platform to help organise complex information into interactive relationship maps. I’m grateful to Christina Bowen, a Kumu-recommended mapper, for her assistance.
The following lists the project data collected to date:
- Project name
- Project description
- Aligned purpose – does the project / product specifically set out to do one or more of:
- Improve privacy
- Improve digital inclusion and equality
- Encourage decentralized or distributed architecture
- None of the above
- Conflicting purpose – intentionally or otherwise, does it:
- Surveil the user to sell the data / insight to third parties
- Facilitate mass state surveillance
- Exclude or discriminate against any individual or group
- Encourage centralization
- None of the above
- Uncertain
- Main website URL
- Small logo URL
- Twitter handle
- Organisation website URL, where appropriate
- Main repository URL
- Software licensing – Artistic License v1.0 / Artistic License v2.0 / CC BY 2.0 / CC BY-SA 2.0 / CC0 / IGPL / Apache License v2 / LPPL v1.2 / LPPL v1.3 / Academic Free License version 3 / EPL v1 / FreeBSD / Modified BSD / GNU GPL v2 / GNU GPL v3 / MIT License / MPL v1.1 / MPL v2.0 / OPL v1.0 / ISC license / Other OSI-approved license / Proprietary commercial software license / Not stated
- Maturity
- Concept
- Alpha
- Beta
- First release
- Latest release
- Programming languages (a selection of 49)
- Documentation languages (a selection of 35)
- Platform dependencies – on which other software projects does a project depend?
- Internetome – at which vertices does the project operate?
- Enhancing the human interface
- Social (incl. co-operation and collaboration)
- Legal
- Semantic (incl. collective knowledge / intelligence / cognition)
- Post-TCP/IP networking
- Consensus protocols / systems
- Level of diligence?
- Apparent – just going off the project's stated purpose / plain English summary
- Inside – edited by a project team member
- Audited – independent technological assessment
- Due diligence – detailed examination for potential investment.
(Note: only those projects for which there is at least one aligned purpose in response to 3. and a response of e. or f. to 4. are included in the map.)
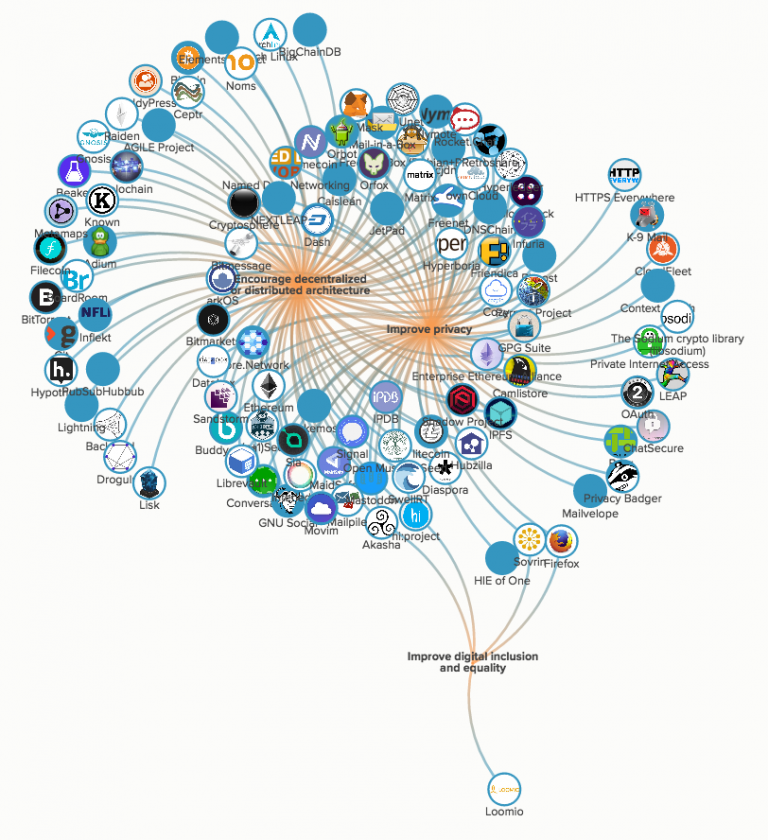
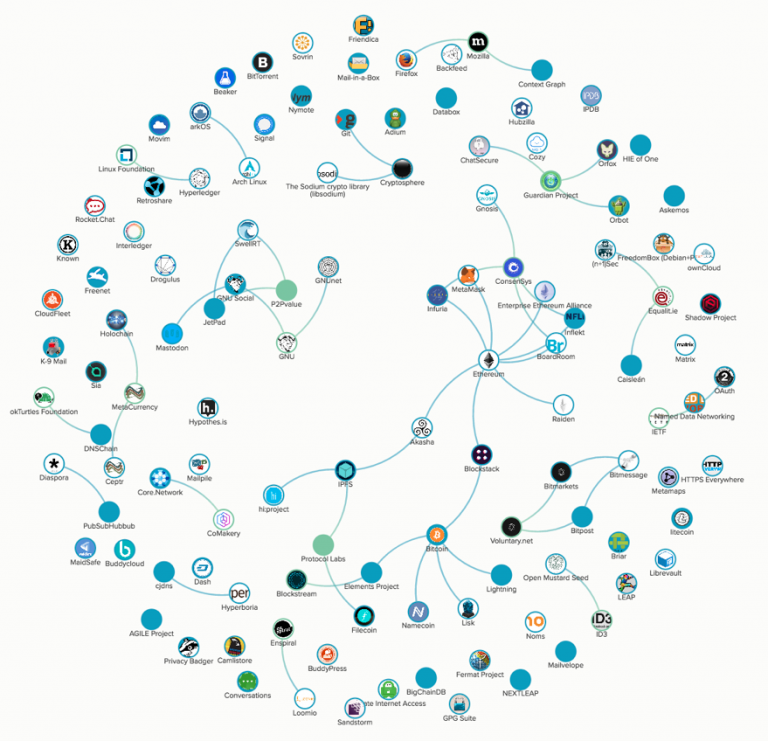
6. Future research
This report has discussed sociology theory and considered the sociotechnical agent specifically in relation to trust, sovereignty, privacy, and decentralisation. It has presented the Internetome, a construct for considering major components of complex sociotechnical systems, and offered a redefinition of ourselves as agencement of the biological, psychological, informational, and interfacial; skin.
I have argued that the interface vertex of the Internetome requires priority attention: it is core to skin; it is the original home of and continuing source of power for the centralising entities and may then also serve a similar role in decentralising; and it appears to be the vertex attracting least attention to date from those intent on decentralisation. Accordingly I have presented the hi:project.
Lastly, I have described the initial work to map the ecosystem of projects intent on enhancing agency in terms of privacy, equality, and decentralisation.
6.1. Research questions
RQ1 – How might we define the sociotechnical agent?
I will continue to develop the concept of skin with further secondary research in the theories of social science and specifically actor-network theory, in complexity, network science, artificial intelligence, and human-computer interaction.
The technologies and associated architecture do not yet exist to accommodate the concept, but I will investigate the requisite technologies (including the hi:project) and discuss their prospects, forming a normative model.
I will invite discussion with experts using purposive sampling relating to expertise in associated disciplines (e.g. sociology, human-computer interaction, web science) and topics (e.g. identity, personal data, social networking, consensus protocols).
I will provide interviewees with a relevant brief in advance to apprise them of the context and encourage reflection on the specific topics ahead of time. I will meet them in person or via video conference service, recording the interviews with the interviewees’ permission for subsequent transcription and analysis. The interviews will be semi-structured: a structure to inform the intitial progression of the interview and ensure appropriate breadth and depth, leaving good time to encourage free-form commentary.
RQ2 – How is this agent effected by current and future technical architectures and services?
With reference to the interviews, published literature, the status quo, and the normative model developed in response to RQ1, I will describe modalities and parameters that enhance or erode the agency of the sociotechnical agent, including in terms of the Internetome vertices, identity, trust, privacy, equality, and decentralisation.
Given the vast array of potential technical combination, this work cannot review each combination systematically. Rather, I will identify inter-connected causes-and-effects rendered as a causal map.
The research will exclude analysis of cryptographic techniques and technologies, presuming the continuous availability of suitable cryptography.
RQ3 – What are the opportunities and challenges for the associated ecosystem of projects?
I will continue to identify, qualify, and analyse projects working to enhance agency per my response to RQ2 across all Internetome vertices, sharing any insights with the ecosystem during the process.
Specifically, the map will be developed by:
- Finding more projects
- I expect to be able to triple the number of projects. I will explore ways in which this may be achieved through crowdsourcing, subject to my verification.
- Extending the data fields collected, for example:
- Type of consensus protocol
- Whether the service may be locked as decentralised? (Recall Facebook’s co-option of OpenID (3.3.1))
- Financing (e.g. foundation, crowd, altcoin)
- Intended dissemination / adoption model
- Barriers to adoption
- Creating Kumu presentations – preset ‘walks’ through the map for those unfamiliar with the Kumu interface, highlighting pertinent insights
- Enabling anyone to embed the map and presentations into websites
- Publishing corresponding RDF dataset to the public domain, possibly using Noms45 to faciliate its distributed maintenance.
I intend for the map to be a dynamic representation of the ecosystem, maintained and used by members of the ecosystem to further their goals. For example, it may help identify: duplications of effort; critical dependencies; critical weaknesses; funding successes and failures; important but under-resourced challenges; synergies and partnering opportunities. At the very least, it should catalyse new connections.
7. Bibliography
Abowd, G.D., Mynatt, E.D., 2000. Charting Past, Present, and Future Research in Ubiquitous Computing. ACM Trans Comput-Hum Interact 7, 29–58. doi:10.1145/344949.344988
Accessible Rich Internet Applications (WAI-ARIA) 1.0 [WWW Document], 2014. URL https://www.w3.org/TR/wai-aria/ (accessed 5.24.16).
Ackoff, R.L., 1989. From data to wisdom. J. Appl. Syst. Anal. 16, 3–9.
Adams, P., 2014. The End Of Apps As We Know Them [WWW Document]. Intercom. URL https://blog.intercom.io/the-end-of-apps-as-we-know-them/ (accessed 6.22.16).
Afanasyev, A., Mahadevan, P., Moiseenko, I., Uzun, E., Zhang, L., 2013. Interest flooding attack and countermeasures in Named Data Networking, in: IFIP Networking Conference, 2013. IEEE, pp. 1–9.
Allen, C., 2016. The Path to Self-Sovereign Identity. Life Alacrity.
Allen, C., 2015. The Four Kinds of Privacy [WWW Document]. URL http://www.lifewithalacrity.com/2015/04/the-four-kinds-of-privacy.html (accessed 2.7.17).
Altman, I., 1975. The Environment and Social Behavior: Privacy, Personal Space, Territory, and Crowding.
Andrejevic, M., 2007. Surveillance in the Digital Enclosure. Commun. Rev. 10, 295–317. doi:10.1080/10714420701715365
Apple, 2014. Apple - Press Info - Apple and IBM Forge Global Partnership to Transform Enterprise Mobility.
Apple Human Interface Guidelines: The Apple Desktop Interface, 1987. . Addison-Wesley.
Archer, M.S., 2003. Structure, Agency and the Internal Conversation. Cambridge University Press.
Archer, M.S., 1995. Realist Social Theory: The Morphogenetic Approach. Cambridge University Press, Cambridge, UK.
Bandura, A., 2006. Toward a Psychology of Human Agency. Perspect. Psychol. Sci. 1, 164–180. doi:10.1111/j.1745-6916.2006.00011.x
Bandura, A., 1997. Self-efficacy: The exercise of control. W H Freeman/Times Books/ Henry Holt & Co, New York, NY, US.
Bandura, A., 1989. Human agency in social cognitive theory. Am. Psychol. 44, 1175–1184. doi:10.1037/0003-066X.44.9.1175
Bandura, A., 1986. Social foundations of thought and action: A social cognitive theory, Prentice-Hall series in social learning theory. Prentice-Hall, Inc, Englewood Cliffs, NJ, US.
Baran, P., 1964. On Distributed Communications (Memorandum). RAND.
Barker, C., 2007. Cultural Studies: Theory and Practice, Third Edition edition. ed. SAGE Publications Ltd.
Barnes, S.B., 2006. A privacy paradox: Social networking in the United States. First Monday 11.
Barry, A., 2001. Political machines: governing a technological society. Athlone Press, London; New York.
Bateson, G., 1972. Steps to an Ecology of Mind: Collected Essays in Anthropology, Psychiatry, Evolution, and Epistemology. University of Chicago Press.
Bazire, M., Brézillon, P., 2005. Understanding Context Before Using It, in: Modeling and Using Context. Presented at the International and Interdisciplinary Conference on Modeling and Using Context, Springer, Berlin, Heidelberg, pp. 29–40. doi:10.1007/11508373_3
Beer, D., 2013. Popular Culture and New Media: The Politics of Circulation. Springer.
Belsky, S., 2014. The Interface Layer: Where Design Commoditizes Tech: A new cohort of design-driven companies are adding a layer of convenience between us and the underlying services and utilities that improve our lives. This could change everything. [WWW Document]. Medium. URL https://medium.com/bridge-collection/the-interface-layer-when-design-commoditizes-tech-e7017872173a#.pj2apl36o (accessed 6.22.16).
Berg, M., 2012. Social intermediaries and the location of agency: a conceptual reconfiguration of social network sites. Contemp. Soc. Sci. 7, 321–333. doi:10.1080/21582041.2012.683446
Berners-Lee, T., 1999. Weaving the Web: The Original Design and Ultimate Destiny of the World Wide Web by Its Inventor. HarperCollins.
Berners-Lee, T., Hendler, J., Lassila, O., others, 2001. The semantic web. Sci. Am. 284, 28–37.
Bhaskar, R., 1989. The possibility of naturalism: a philosophical critique of the contemporary human sciences, 2nd ed. Harvester Wheatsheaf, London; New York.
Bhaskar, R., 1979. The Possibility of Naturalism: A Philosophical Critique of the Contemporary Human Sciences, 1st ed. Humanities Press.
Bode, M., Kristensen, D.B., 2016. The digital doppelgänger within: A study on self-tracking and the quantified self movement. Assem. Consum. Res. Actors Netw. Mark. N. Y. NY Routledge.
Boyd, D., 2004. why privacy issues matter… to me. apophenia.
Bratton, B.H., 2015. The Stack: On Software and Sovereignty. MIT Press.
Byrne, D., Callaghan, G., 2013. Complexity Theory and the Social Sciences: The state of the art. Routledge.
Cafaro, F., 2012. Using embodied allegories to design gesture suites for human-data interaction, in: Proceedings of the 2012 ACM Conference on Ubiquitous Computing. ACM, pp. 560–563.
Callon, M., 2005. Economic Sociology – European Electronic Newsletter.
Calvary, G., Coutaz, J., Thevenin, D., Bouillon, L., Florins, M., Limbourg, Q., Souchon, N., Vanderdonckt, J., Marucci, L., Paternò, F., Santoro, C., 2002. The CAMELEON Reference Framework, R&D Project IST-2000-30104.
Casteleyn, S., Garrig’os, I., Maz’on, J.-N., 2014. Ten Years of Rich Internet Applications: A Systematic Mapping Study, and Beyond. ACM Trans Web 8, 18:1–18:46. doi:10.1145/2626369
Castells, M., 2002. The Internet Galaxy: Reflections on the Internet, Business, and Society. OUP Oxford.
Cavoukian, A., 2011. Smartprivacy for the smart grid: embedding privacy into the design of electricity conservation.
Checkland, P., 1988. The case for “holon.” Syst. Pract. Action Res. 1, 235–238.
Chilling Effects: NSA Surveillance Drives U.S. Writers to Self-Censor, 2013. . PEN America.
Chopra, A.K., Singh, M.P., 2016. From Social Machines to Social Protocols: Software Engineering Foundations for Sociotechnical Systems, in: Proceedings of the 25th International Conference on World Wide Web, WWW ’16. International World Wide Web Conferences Steering Committee, Republic and Canton of Geneva, Switzerland, pp. 903–914. doi:10.1145/2872427.2883018
Christl, W., Spiekermann, S., 2016. Networks of Control A Report on Corporate Surveillance, Digital Tracking, Big Data & Privacy. Facultas, Vienna.
CLARK, A., 2007. Re-Inventing Ourselves: The Plasticity of Embodiment, Sensing, and Mind. J. Med. Philos. 32, 263–282. doi:10.1080/03605310701397024
Cohen, J.E., 2014. Configuring the Networked Self: Law, Code, and the Play of Everyday Practice. Yale University Press.
Coleman, S., Blumler, J.G., 2009. The Internet and Democratic Citizenship: Theory, Practice and Policy. Cambridge University Press, Cambridge.
Company Info | Facebook Newsroom [WWW Document], 2017. URL https://newsroom.fb.com/Company-Info/ (accessed 4.7.17).
Composite Capability/Preference Profiles (CC/PP): Structure and Vocabularies 1.0 [WWW Document], 2004. URL https://www.w3.org/TR/CCPP-struct-vocab/ (accessed 5.23.16).
Cook, T., 2016. Customer Letter.
Couldry, N., 2014. Inaugural: A necessary disenchantment: myth, agency and injustice in a digital world: A necessary disenchantment. Sociol. Rev. 62, 880–897. doi:10.1111/1467-954X.12158
Coulouris, G.F., Dollimore, J., Kindberg, T., 2005. Distributed Systems: Concepts and Design. Pearson Education.
Coutaz, J., Rey, G., 2002. Foundations for a Theory of Contextors, in: Kolski, C., Vanderdonckt, J. (Eds.), Computer-Aided Design of User Interfaces III. Springer Netherlands, pp. 13–33. doi:10.1007/978-94-010-0421-3_2
Crabtree, A., Mortier, R., 2016. Personal Data, Privacy and the Internet of Things: The Shifting Locus of Agency and Control (SSRN Scholarly Paper No. ID 2874312). Social Science Research Network, Rochester, NY.
David W., H., 2012. Jean-François Lyotard and the Inhumanity of Internet Surveillance, in: Fuchs, C. (Ed.), Internet and Surveillance: The Challenges of Web 2.0 and Social Media. Routledge.
Davis, L.J., 2002. Bending Over Backwards: Essays on Disability and the Body. NYU Press.
Deleuze, G., 1992. Postscript on the Societies of Control. October 59, 3–7.
Dey, A.K., Abowd, G.D., Salber, D., 2001. A Conceptual Framework and a Toolkit for Supporting the Rapid Prototyping of Context-aware Applications. Hum-Comput Interact 16, 97–166. doi:10.1207/S15327051HCI16234_02
Dourish, P., 2004. What we talk about when we talk about context. Pers. Ubiquitous Comput. 8, 19–30. doi:10.1007/s00779-003-0253-8
Elmqvist, N., 2011a. Distributed User Interfaces: State of the Art, in: Gallud, J.A., Tesoriero, R., Penichet, V.M.R. (Eds.), Distributed User Interfaces, Human-Computer Interaction Series. Springer London, pp. 1–12. doi:10.1007/978-1-4471-2271-5_1
Elmqvist, N., 2011b. Embodied Human-Data Interaction, in: Proceedings of the CHI Workshop on Embodied Interaction: Theory and Practice in HCI. Presented at the CHI 2011, ACM, Vancouver, Canada, pp. 104–107.
Eslami, M., Rickman, A., Vaccaro, K., Aleyasen, A., Vuong, A., Karahalios, K., Hamilton, K., Sandvig, C., 2015. “I Always Assumed That I Wasn’T Really That Close to [Her]”: Reasoning About Invisible Algorithms in News Feeds, in: Proceedings of the 33rd Annual ACM Conference on Human Factors in Computing Systems, CHI ’15. ACM, New York, NY, USA, pp. 153–162. doi:10.1145/2702123.2702556
Evans, B., 2015. Mobile is not a neutral platform [WWW Document]. Benedict Evans. URL http://ben-evans.com/benedictevans/2015/9/26/mobile-is-not-a-neutral-platform (accessed 6.22.16).
Ezrachi, A., Stucke, M.E., 2016. Virtual Competition: The Promise and Perils of the Algorithm-Driven Economy. Harvard University Press, Cambridge, Massachusetts.
Floridi, L., 2005. The Ontological Interpretation of Informational Privacy. Ethics Inf. Technol. 7, 185–200. doi:10.1007/s10676-006-0001-7
France-Presse, A., 2016. Iceland’s Pirate party invited to form government. The Guardian.
Fuchs, C., Boersma, K., Albrechtslund, A., Sandoval, M., 2012. Introduction: Internet and Surveillance, in: Internet and Surveillance: The Challenges of Web 2.0 and Social Media. Routledge.
Galloway, A.R., 2012. The Interface Effect. Polity.
Gartner, 2017. Gartner Says Worldwide Sales of Smartphones Grew 7 Percent in the Fourth Quarter of 2016.
Giddens, A., 1986. The Constitution of Society: Outline of the Theory of Structuration. University of California Press.
Giddens, A., Sutton, P.W., 2014. Essential Concepts in Sociology. John Wiley & Sons.
Google, 2012. Knowledge – Inside Search – Google [WWW Document]. Knowl. Graph. URL https://www.google.com/intl/es419/insidesearch/features/search/knowledge.html (accessed 4.7.17).
Grandjean, E., Kroemer, K.H.E., 1997. Fitting The Task To The Human, Fifth Edition: A Textbook Of Occupational Ergonomics. CRC Press.
Gürses, S., Alamo, J.M. del, 2016. Privacy Engineering: Shaping an Emerging Field of Research and Practice. IEEE Secur. Priv. 14, 40–46. doi:10.1109/MSP.2016.37
Gustin, S., 2017. Senate Republicans Vote to Allow ISPs to Sell Your Private Data [WWW Document]. Motherboard. URL https://motherboard.vice.com/en_us/article/senate-republicans-vote-to-allow-isps-to-sell-your-private-data (accessed 3.29.17).
Haggerty, K.D., Ericson, R.V., 2000. The surveillant assemblage. Br. J. Sociol. 51, 605–622. doi:10.1080/00071310020015280
Hardin, R., 2002. Trust and Trustworthiness (Russell Sage Foundation Series on Trust). Russell Sage Foundation.
Hardy, Q., 2016. The Web’s Creator Looks to Reinvent It. N. Y. Times.
He, J., Yen, I.L., Peng, T., Dong, J., Bastani, F., 2008. An Adaptive User Interface Generation Framework for Web Services, in: IEEE Congress on Services Part II, 2008. SERVICES-2. Presented at the IEEE Congress on Services Part II, 2008. SERVICES-2, pp. 175–182. doi:10.1109/SERVICES-2.2008.23
Heersmink, R., 2016. Distributed selves: personal identity and extended memory systems. Synthese. doi:10.1007/s11229-016-1102-4
Hillman, R.A., Rachlinski, J.J., 2001. Standard-Form Contracting in the Electronic Age (SSRN Scholarly Paper No. ID 287819). Social Science Research Network, Rochester, NY.
Hope, C., 2015. Spies should be able to monitor all online messaging, says David Cameron. The Telegraph.
Hürsch, W.L., Lopes, C.V., 1995. Separation of Concerns.
Huxley, A., 1937. Ends and Means: An Inquiry Into the Nature of Ideals and Into the Methods Employed for Their Realization. Transaction Publishers.
IBM, 2015. IBM’s New Watson Health Unit Changes the Game.
Internet Society, 2017. Internet Society DNS Privacy Workshop @ NDSS 2017 [WWW Document]. URL https://portal.sinodun.com/wiki/display/TDNS/DNS+Privacy+Workshop+@+NDSS+2017 (accessed 4.7.17).
Introduction to Model-Based User Interfaces [WWW Document], 2014. . W3C. URL https://www.w3.org/TR/2014/NOTE-mbui-intro-20140107/ (accessed 2.9.17).
Jacob, P., 2014. Intentionality.
Jarrett, K., 2008. Interactivity is Evil! A critical investigation of Web 2.0. First Monday 13.
Johnson, N.F., 2007. Two’s company, three is complexity: a simple guide to the science of all sciences. Oneworld.
Kovachev, D., Renzel, D., Nicolaescu, P., Klamma, R., 2013. DireWolf - Distributing and Migrating User Interfaces for Widget-based Web Applications — Informatik 5 (Information Systems), in: The 13th International Conference on Web Engineering. Presented at the ICWE13, Springer Verlag, Aalborg, DK.
Lamsweerde, A. van, 2009. Requirements Engineering: From System Goals to UML Models to Software Specifications. Wiley.
Lanier, J., 2013. Who Owns The Future? Allen Lane.
Lapowsky, I., 2016. Of Course Facebook Is Biased. That’s How Tech Works Today [WWW Document]. WIRED Mag. URL http://www.wired.com/2016/05/course-facebook-biased-thats-tech-works-today/ (accessed 5.12.16).
Lash, S., 2007. Power after Hegemony Cultural Studies in Mutation? Theory Cult. Soc. 24, 55–78. doi:10.1177/0263276407075956
Lash, S., 2002. Critique of Information. SAGE.
Latour, B., 2005. Reassembling the Social: An Introduction to Actor-Network-Theory. OUP Oxford.
Lee, D., 2016. Facebook: Political bias claim “untrue.” BBC News.
Levy, S., 1984. Hackers: Heroes of the Computer Revolution. Anchor, Garden City, N.Y.
Lewes, G.H., 1875. Problems of life and mind.
Lewis, A., 2010. User-driven discontent [WWW Document]. MetaFilter. URL http://www.metafilter.com/95152/Userdriven-discontent#3256046 (accessed 4.27.16).
Liu, X., Vega, K., Maes, P., Paradiso, J.A., 2016. Wearability Factors for Skin Interfaces, in: Proceedings of the 7th Augmented Human International Conference 2016, AH ’16. ACM, New York, NY, USA, p. 21:1–21:8. doi:10.1145/2875194.2875248
Loffreto, D., 2016. Self-Sovereign Identity. Moxy Tongue.
Loffreto, D., 2012. What is “Sovereign Source Authority”? Moxy Tongue.
Loffreto, D., 2011. Facebook Data Structure Is Evil. Moxy Tongue.
Lukas, A., 2014. Health Datapalooza 2014: Adriana Lukas Keynote Address. Washington DC, USA.
Mayer, R.C., Davis, J.H., Schoorman, F.D., 1995. An Integrative Model of Organizational Trust. Acad. Manage. Rev. 20, 709–734. doi:10.2307/258792
MBUI - Glossary [WWW Document], 2014. . W3C. URL https://www.w3.org/TR/2014/NOTE-mbui-glossary-20140107/ (accessed 2.9.17).
McCrossan, A., 2015. 2.3 On agency. Emergent Code Chron.
McLuhan, M., 1964. Understanding media: the extensions of man. McGraw-Hill.
McLuhan, M., 1962. The Gutenberg Galaxy: The Making of Typographic Man. University of Toronto Press.
Meeker, M., 2014. Internet trends 2014 – code conference.
Meichenbaum, D., 1985. Teaching thinking: A cognitive-behavioral perspective., in: Chipman, S.F., Segal, J.W., Glaser, R. (Eds.), Thinking and Learning Skills: Volume 2: Research and Open Questions. Routledge, pp. 407–426.
Melchior, J., Grolaux, D., Vanderdonckt, J., Van Roy, P., 2009. A Toolkit for Peer-to-peer Distributed User Interfaces: Concepts, Implementation, and Applications, in: Proceedings of the 1st ACM SIGCHI Symposium on Engineering Interactive Computing Systems, EICS ’09. ACM, New York, NY, USA, pp. 69–78. doi:10.1145/1570433.1570449
Mikkonen, T., Systä, K., Pautasso, C., 2015. Towards Liquid Web Applications, in: Cimiano, P., Frasincar, F., Houben, G.-J., Schwabe, D. (Eds.), Engineering the Web in the Big Data Era, Lecture Notes in Computer Science. Springer International Publishing, pp. 134–143. doi:10.1007/978-3-319-19890-3_10
Model-Based UI XG Final Report (W3C Incubator Group Report), 2010.
Mol, A., 2002. The Body Multiple: Ontology in Medical Practice. Duke University Press.
Mortier, R., Haddadi, H., Henderson, T., McAuley, D., Crowcroft, J., 2014. Human-Data Interaction: The Human Face of the Data-Driven Society (SSRN Scholarly Paper No. ID 2508051). Social Science Research Network, Rochester, NY.
Mortier, R., Haddadi, H., Henderson, T., McAuley, D., Crowcroft, J., 2013. Challenges & opportunities in human-data interaction. Presented at the The Fourth Digital Economy All-hands Meeting: Open Digital (DE), Salford, Citeseer.
Mortier, R., Zhao, J., Crowcroft, J., Qi Li, L.W., Haddadi, H., Amar, Y., Crabtree, A., Colley, J., Lodge, T., Brown, A., McAuley, D., Greenhalgh, C., 2016. Personal data management with the Databox: what’s inside the box? Presented at the ACM CoNEXT Workshop on Cloud-Assisted Networking (CoNEXT 2016), Irvine, California, USA, pp. 49–54.
Negroponte, N., 1995. Being digital. Vintage Books.
Nissenbaum, H., 2004. Privacy as contextual integrity. Wash Rev 79, 119.
O’Hara, K., 2017a. What is privacy and why can’t we agree about it?
O’Hara, K., 2017b. Smart Contracts-Dumb Idea. IEEE Internet Comput. 21, 97–101.
O’Hara, K., 2016. The Seven Veils of Privacy. IEEE Internet Comput. 20, 86–91. doi:10.1109/MIC.2016.34
O’Hara, K., 2013. Web Science: Understanding the Emergence of Macro-Level Features on the World Wide Web. Found. Trends® Web Sci. 4, 103–267. doi:10.1561/1800000017
O’Hara, K., Hutton, W., 2004. Trust: ..From Socrates to Spin. Icon Books Ltd, Duxford.
O’Hara, K., Shadbolt, N., 2008. The Spy In The Coffee Machine: The End of Privacy as We Know it. Oneworld Publications.
Parsons, T., 1935. The Place of Ultimate Values in Sociological Theory. Int. J. Ethics 45, 282–316.
Pasquale, F., 2015. The Black Box Society: The Secret Algorithms That Control Money and Information. Harvard University Press.
Paterno’, F., Santoro, C., Spano, L.D., 2010. MARIA: A universal, declarative, multiple abstraction-level language for service-oriented applications in ubiquitous environments. ACM Trans. Comput.-Hum. Interact. 16, 1–30. doi:10.1145/1614390.1614394
Pavlus, J., 2015. Apple and Google Race to See Who Can Kill the App First [WWW Document]. WIRED. URL http://www.wired.com/2015/06/apple-google-ecosystem/ (accessed 6.22.16).
Perera, C., Zaslavsky, A., Christen, P., Georgakopoulos, D., 2014. Context Aware Computing for The Internet of Things: A Survey. IEEE Commun. Surv. Tutor. 16, 414–454. doi:10.1109/SURV.2013.042313.00197
Phillips, J., 2006. Agencement/Assemblage. Theory Cult. Soc. 23, 108–109. doi:10.1177/026327640602300219
Privacy Paradox from the Note to Self podcast, WNYC (New York Public Radio) [WWW Document], 2017. . Priv. Paradox. URL http://privacyparadox.com (accessed 4.5.17).
Rajchman, J., 2000. The Deleuze Connections. MIT Press.
Ramasubramanian, V., Sirer, E.G., 2005. Perils of transitive trust in the domain name system, in: Proceedings of the 5th ACM SIGCOMM Conference on Internet Measurement. USENIX Association, pp. 35–35.
Raskin, J., 2000. The Humane Interface: New Directions for Designing Interactive Systems. Addison-Wesley Professional.
REGULATION (EU) 2016/679 OF THE EUROPEAN PARLIAMENT AND OF THE COUNCIL, 2016.
Resolution on Privacy by Design, the 32nd International Conference of Data Protection and Privacy Commissioners, 2010.
Ricoeur, P., 2003. The Rule of Metaphor: The Creation of Meaning in Language. Psychology Press.
Rivest, R.L., Shamir, A., Adleman, L., 1978. A Method for Obtaining Digital Signatures and Public-key Cryptosystems. Commun ACM 21, 120–126. doi:10.1145/359340.359342
Ruppert, E., 2011. Population Objects: Interpassive Subjects. Sociology 45, 218–233. doi:10.1177/0038038510394027
Russell, D.M., Stefik, M.J., Pirolli, P., Card, S.K., 1993. The Cost Structure of Sensemaking, in: Proceedings of the INTERACT ’93 and CHI ’93 Conference on Human Factors in Computing Systems, CHI ’93. ACM, New York, NY, USA, pp. 269–276. doi:10.1145/169059.169209
Sambra, A., Sheldrake, P., 2015. The hi:project blog: Solid – an introduction by MIT CSAIL’s Andrei Sambra [WWW Document]. The hi:project. URL http://hi-project.org/2015/12/solid-introduction-mit-csails-andrei-sambra/ (accessed 6.21.16).
Sambra, A.V., Mansour, E., Hawke, S., Zereba, M., Greco, N., Ghanem, A., Zagidulin, D., Aboulnaga, A., Berners-Lee, T., n.d. Solid: A Platform for Decentralized Social Applications Based on Linked Data.
Schilit, B.N., Theimer, M.M., 1994. Disseminating active map information to mobile hosts. IEEE Netw. 8, 22–32. doi:10.1109/65.313011
Schumacher, E.F., 1973. Small Is Beautiful: A Study of Economics as if People Mattered. Harper, New York.
Schunk, D.H., Zimmerman, B.J. (Eds.), 1994. Self-regulation of learning and performance: Issues and educational applications. Lawrence Erlbaum Associates, Inc, Hillsdale, NJ, England.
Searls, D., 2012. The Intention Economy: When Customers Take Charge. Harvard Business Press.
Serra, R., Schoolman, C.F., 1973. Television Delivers People.
Sheldrake, P., 2016a. Defining Sovereign Technology, so we can build it, and so we know it when we see it. Philip Sheldrake.
Sheldrake, P., 2016b. Redecentralisation: A deep cause of causes you care about deeply [WWW Document]. World Wide Web Found. URL http://webfoundation.org/2016/10/redecentralisation-a-deep-cause-of-causes-you-care-about-deeply/ (accessed 2.14.17).
Sheldrake, P., 2015a. The human web and sustainability by Philip Sheldrake. Glob. Peter Drucker Forum.
Sheldrake, P., 2015b. Open up to the GDPR and the IoT. The hi:project.
Sheldrake, P., 2015c. Questions of VRM, privacy and consent, advertising and technology. The hi:project.
Sheldrake, P., 2015d. Decentralization cannot be marketed. The hi:project.
Simon, H.A., 1971. Designing organizations for an information-rich world.
Smart, P.R., Simperl, E., Shadbolt, N., 2014. A Taxonomic Framework for Social Machines, in: Miorandi, D., Maltese, V., Rovatsos, M., Nijholt, A., Stewart, J. (Eds.), Social Collective Intelligence: Combining the Powers of Humans and Machines to Build a Smarter Society. Springer, pp. 51–85.
Solove, D.J., 2008. Understanding Privacy. Harvard University Press.
Strate, L., 1999. The varieties of cyberspace: Problems in definition and delimitation. West. J. Commun. 63, 382–412. doi:10.1080/10570319909374648
Sunstein, C.R., Thaler, R.H., 2009. Nudge: Improving Decisions About Health, Wealth and Happiness. Penguin, London.
The Economist, 2017. Amazon, the world’s most remarkable firm, is just getting started [WWW Document]. The Economist. URL http://www.economist.com/news/leaders/21719487-amazon-has-potential-meet-expectations-investors-success-will-bring-big (accessed 4.7.17).
The hi:project: Champions [WWW Document], 2016. . The hi:project. URL http://hi-project.org/champions/ (accessed 6.21.16).
The hi:project website homepage [WWW Document], 2016. . The hi:project. URL http://hi-project.org/ (accessed 7.10.16).
Thiel, P., 2014. Competition Is for Losers. Wall Str. J.
Thomson, J.J., 1975. The Right to Privacy. Philos. Public Aff. 4, 295–314.
Thrift, N., 2014. The promise of urban informatics: some speculations. Environ. Plan. A 46, 1263–1266. doi:10.1068/a472c
UK Government, 2016. UK government response to EU public consultation on digital platforms.
User Modeling for Accessibility Online Symposium [WWW Document], 2013. . W3C Web Access. Initiat. URL https://www.w3.org/WAI/RD/2013/user-modeling/Overview.html (accessed 5.23.16).
Vargas, E., Latour, B., Karsenti, B., Aït-Touati, F., Salmon, L., 2008. The Tarde Durkheim Debate, 1903: a recension. English translation.
Walsh, K., 2015. Automakers Say You Don’t Really Own Your Car [WWW Document]. Electron. Front. Found. URL https://www.eff.org/deeplinks/2015/04/automakers-say-you-dont-really-own-your-car (accessed 3.16.17).
Warren, S.D., Brandeis, L.D., 1890. The Right to Privacy. Harv. Law Rev. 4, 193–220. doi:10.2307/1321160
Weinberger, M., 2016. Microsoft just made a deal with IBM — and Apple should be nervous [WWW Document]. Bus. Insid. URL http://uk.businessinsider.com/microsoft-ibm-surface-partnership-2016-7 (accessed 4.10.17).
What They Know - Wsj.com, 2010. . Wall Str. J.
Wiener, N., 1950. The Human Use Of Human Beings: Cybernetics And Society. Houghton Mifflin.
William A. Jackson, 1999. Dualism, duality and the complexity of economic institutions. Int. J. Soc. Econ. 26, 545–558. doi:10.1108/03068299910215997
Windley, P., 2016. Self-Sovereign Identity and Legal Identity [WWW Document]. URL http://www.windley.com/archives/2016/04/self-sovereign_identity_and_legal_identity.shtml (accessed 4.11.17).
Wise, J., 2011. Assemblage, in: Stivale, C.J. (Ed.), Gilles Deleuze: Key Concepts. Acumen.
Wistreich, N., 2015. What might a Coop Uber look like? (or should we be thinking bigger)? | Hello Ideas [WWW Document]. URL https://helloideas.com/ideas/what-might-coop-uber-look-or-should-we-be-thinking-bigger (accessed 4.5.17).
Yadron, D., 2016. Facebook and Twitter back Apple in phone encryption battle with FBI. The Guardian.
Zhang, L., Afanasyev, A., Burke, J., Jacobson, V., Crowley, P., Papadopoulos, C., Wang, L., Zhang, B., others, 2014. Named data networking. ACM SIGCOMM Comput. Commun. Rev. 44, 66–73.
Zittrain, J., 2012. Meme patrol: “When something online is free, you’re not the customer, you’re the product.” Future Internet - Stop It.
Zuboff, S., 2015. Big Other: Surveillance Capitalism and the Prospects of an Information Civilization (SSRN Scholarly Paper No. ID 2594754). Social Science Research Network, Rochester, NY.
Zuckerberg, M., 2017. Building Global Community [WWW Document]. URL https://www.facebook.com/notes/mark-zuckerberg/building-global-community/10103508221158471/?pnref=story (accessed 4.7.17).
1.
I was a board director of techUK, the UK’s tech industry association, from 2005 to 2016.
2.
One response to the commercial challenge is the altcoin – a neologism formed from ‘bitcoin alternative’. By predicating distributed service on a blockchain the project originators have the opportunity to see the corresponding cryptocurrency inflate with the popularity of the service, thereby inflating the value of their ‘pre-mine’ i.e. the quantity of the altcoin kept for the originators by way of a return on investment. However, pre-mines, and variations known as instamines, ninjamines, and fastmines, have become associated with and therefore tarnished by so-called pump and dump schemes and may therefore prove a less realistic mechanism by which to secure a return on investment in the future.
3.
Archer (2003) slightly misquotes Bhaskar in writing: “… through social agency”
4.
As the layers in ‘The Stack’, Bratton capitalises Earth, Cloud, City, Address, Interface and User.
5.
humans sharing subject/ agency with inhuman forms has many pros.. not mere resignation
— Benjamin Bratton (@bratton) March 23, 2017
12.
Written for the Digital Life Collective, not yet published.
13.
Alice and Bob are popular placeholder names in computer science, harking back to the 1970s (Rivest et al., 1978).
15.
Ibid. 13
16.
18.
28.
Note: this very statement already represents a partial translation of data into information i.e. qualifying that kWh refers to electricity use, calculating the difference in meter readings, and translating the dates concerned into “last month”. The data would look more like: 98665, 31032016, 23:59; 99108, 30042016, 23:59; 103562, 31032017, 23:59; 103962, 30042017, 23:59.
29.
Ibid. 13
32.
The project acquired its current name January 2014
33.
A Google search estimates 61,000,000 results for “user interface” and 411,000 for “human interface”, 14:42, 21 June 2016, NoCountryRedirect, English language
34.
Ibid. 13
36.
Likely a NDN over IP, at least prior to any possible future transition away from IP towards pure NDN.
37.
Ibid. 17
38.
Ibid. 18
39.
Ibid. 19
41.
Ibid 20
43.
The Digital Life Collective, www.diglife.com
44.
If this link does not work in future, please visit philipsheldrake.com/research for a current link.
45.